MySQL,mysql2,ORM
1. 基础认知
1.1. 为什么需要数据库?
任何的软件系统都需要存放大量的数据,这些数据通常是非常复杂和庞大的:
- 比如用户信息包括姓名、年龄、性别、地址、身份证号、出生日期等等;
- 比如商品信息包括商品的名称、描述、价格(原价)、分类标签、商品图片等等;
- 比如歌曲信息包括歌曲的名称、歌手、专辑、歌曲时长、歌词信息、封面图片等等;
那么这些信息不能直接存储到文件中吗?可以,但是文件系统有很多的缺点:
很难以合适的方式组织数据(多张表之前的关系合理组织);
并且对数据进行增删改查中的复杂操作(虽然一些简单确实可以),并且保证单操作的原子性;
很难进行数据共享,比如一个数据库需要为多个程序服务,如何进行很好的数据共享;
需要考虑如何进行数据的高效备份、迁移、恢复;
…
数据库通俗来讲就是一个存储数据的仓库,数据库本质上就是一个软件,一个程序
1.2. 常见的数据库有哪些?
通常数据被划分成两类:
- 关系型数据库
- 非关系型数据库;
关系型数据库:MySQL、Oracle、DB2、SQL Server、Postgre SQL等;
- 关系型数据库通常创建很多个二维数据表;
- 数据表之间相互关联起来,形成一对一、一对多、多对对等关系;
- 之后可以利用SQL语句在多张表中查询所需的数据;
- 支持事务,对数据的访问更加的安全;
非关系型数据库:MongoDB、Redis、Memcached、HBse等;
- 非关系型数据库的英文其实是Not only SQL,也简称为NoSQL;
- 相当而已非关系型数据库比较简单一些,存储数据也会更加自由(甚至可以直接将一个复杂的json对象直接塞入到数据库中);
- NoSQL是基于Key-Value的对应关系,并且查询的过程中不需要经过SQL解析,所以性能更高;
- NoSQL通常不支持事物,需要在自己的程序中来保证一些原子性的操作;
如何在开发中选择呢?
- 具体的选择会根据不同的项目进行综合的分析
- 目前在公司进行后端开发(Node、Java、Go等),还是以关系型数据库为主;
- 比较常用的用到非关系型数据库的,在爬取大量的数据进行存储时,会比较常见;
1.3. 认识MySQL
MySQL的介绍:
MySQL原本是一个开源的数据库,原开发者为瑞典的MySQL AB公司;
在2008年被Sun公司收购;
在2009年,Sun被Oracle收购;
所以目前MySQL归属于Oracle;
MySQL是一个关系型数据库,其实本质上就是一款软件、一个程序:
这个程序中管理着多个数据库;
每个数据库中可以有多张表;
每个表中可以由多条数据;
1.4. 数据组织方式

1.5. 下载MySQL软件
- 下载地址:https://dev.mysql.com/downloads/mysql/
- 根据自己的操作系统下载即可;
- 推荐直接下载安装版本,在安装过程中会配置一些环境变量;
- Windows推荐下载MSI的版本;
- Mac推荐下载DMG的版本;
1.6. 终端操作数据库
1.6.1. 连接数据库
方式一:
1
mysql -u[管理员账号] -p[密码]
方式二
1
2mysql -uroot -p
Enter password: your password
1.6.2. 显示数据库
一个数据库软件中,可以包含很多个数据库,如何查看数据库?
1
show databases;
运行语句
1
2
3
4
5
6
7
8
9
10
11
12
13
14Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.15 sec)
mysql>MySQL默认的数据库
infomation_schema:信息数据库,其中包括MySQL在维护的其他数据库、表、列、访问权限等信息;performance_schema:性能数据库,记录着MySQL Server数据库引擎在运行过程中的一些资源消耗相关的信息;mysql:用于存储数据库管理者的用户信息、权限信息以及一些日志信息等;sys:相当于是一个简易版的performance_schema,将性能数据库中的数据汇总成更容易理解的形式;
1.6.3. 创建数据库-表
在终端直接创建一个新的数据库coderhub(一般情况下一个新的项目会对应一个新的数据库)
1
mysql> create database coderhub;
使用创建的数据库coderhub:
1
mysql> use coderhub;
在数据中,创建一张表:
1
2
3
4
5
6mysql> create table user(
-> name varchar(20),
-> age int,
-> height double
-> };
mysql>插入数据
1
mysql> insert into user (name, age, height) values ('why', 18, 1.88);
查看数据
1
mysql> select * from user;
1.7. GUI工具的介绍
- 在终端操作数据库有很多不方便的地方:
- 语句写出来没有高亮,并且不会有任何的提示;
- 复杂的语句分成多行,格式看起来并不美观,很容易出现错误;
- 终端中查看所有的数据库或者表非常的不直观和不方便;
- …
- 所以在开发中,借助于一些GUI工具来连接数据库,之后直接在GUI工具中操作就会非常方便
- 常见的MySQL的GUI工具有很多:
Navicat:收费;- SQLYog:一款免费的SQL工具;
- TablePlus:常用功能都可以使用,但是会多一些限制(比如只能开两个标签页);
2. SQL语句
2.1. 认识SQL
- 操作数据库(特别是在程序中),就需要有和数据库沟通的语言,这个语言就是SQL
- SQL是Structured Query Language,称之为结构化查询语言,简称SQL;
- 使用SQL编写出来的语句,就称之为SQL语句;
- SQL语句可以用于对数据库进行操作;
- 事实上,常见的关系型数据库SQL语句都是比较相似的
- SQL语句的常用规范
- 通常关键字是大写的,比如CREATE、TABLE、SHOW等等;
- 一条语句结束后,需要以 ; 结尾;
- 如果遇到关键字作为表明或者字段名称,可以使用``包裹;
2.2. SQL语句的分类
DDL(Data Definition Language):数据定义语言;
- 可以通过DDL语句对数据库或者表进行:创建、删除、修改等操作;
DML(Data Manipulation Language):数据操作语言;
- 可以通过DML语句对表进行:添加、删除、修改等操作;
DQL(Data Query Language):数据查询语言;
- 可以通过DQL从数据库中查询记录;(重点)
DCL(Data Control Language):数据控制语言;
- 对数据库、表格的权限进行相关访问控制操作;
2.3. DDL - 数据库的操作
1 | # 查看所有的数据库 |
- utf8mb4:可以存储emoji表情
- utf8mb4_0900_ai_ci:排序规则
- ai 不区分轻重音
- ci 不区分大小写
2.4. SQL的数据类型
MySQL支持的数据类型有:数字类型,日期和时间类型,字符串(字符和字节)类型,空间类型和 JSON数据类型
2.4.1. 数字类型
MySQL的数字类型有很多:
整数数字类型:INTEGER,INT,SMALLINT,TINYINT,MEDIUMINT,BIGINT;
类型 存储 (字节) 最小值 无符号最小值 最大值 无符号最大值 TINYINT1 -128 0 127 255 SMALLINT2 -32768 0 32767 65535 MEDIUMINT3 -8388608 0 8388607 16777215 INT4 -2147483648 0 2147483647 4294967295 BIGINT8 -$2^{63}$ 0 $2^{63}$-1 $2^{64}$-1 浮点数字类型:FLOAT,DOUBLE(FLOAT是4个字节,DOUBLE是8个字);
精确数字类型:DECIMAL,NUMERIC(DECIMAL是NUMERIC的实现形式);
1
2
3
4
5
6create table if not exists `users`(
`name` varchar(255),
`age` int,
-- 保留两位小数
`height` decimal(10,2)
);
2.4.2. 日期类型
YEAR以YYYY格式显示值- 范围 1901到2155,和 0000。
DATE类型用于具有日期部分但没有时间部分的值:- DATE以格式YYYY-MM-DD显示值 ;
- 支持的范围是 ‘1000-01-01’ 到 ‘9999-12-31’;
DATETIME类型用于包含日期和时间部分的值:- DATETIME以格式’YYYY-MM-DD hh:mm:ss’显示值;
- 支持的范围是1000-01-01 00:00:00到9999-12-31 23:59:59;
TIMESTAMP数据类型被用于同时包含日期和时间部分的值:- TIMESTAMP以格式’YYYY-MM-DD hh:mm:ss’显示值;
- 但是它的范围是UTC的时间范围:’1970-01-01 00:00:01’到’2038-01-19 03:14:07’;
DATETIME或TIMESTAMP值可以包括在高达微秒(6位)精度的后小数秒一部分- 比如DATETIME表示的范围可以是’1000-01-01 00:00:00.000000’到’9999-12-31 23:59:59.999999’;
2.4.3. 字符串类型
CHAR类型在创建表时为固定长度,长度可以是0到255之间的任何值;- 在被查询时,会删除后面的空格;
VARCHAR类型的值是可变长度的字符串,长度可以指定为0到65535之间的值;- 在被查询时,不会删除后面的空格;
BINARY和VARBINARY类型用于存储二进制字符串,存储的是字节字符串;BLOB用于存储大的二进制类型;TEXT用于存储大的字符串类型;
2.5. 表约束
2.5.1. 主键:PRIMARY KEY
- 一张表中,为了区分每一条记录的唯一性,必须有一个字段是永远不会重复,并且不会为空的,这个字段通常会将它设置为主键:
- 主键是表中唯一的索引;
- 并且必须是NOT NULL的,如果没有设置 NOT NULL,那么MySQL也会隐式的设置为NOT NULL;
- 主键也可以是多列索引,PRIMARY KEY(key_part, …),一般称之为联合主键;
- 建议:开发中主键字段应该是和业务无关的,尽量不要使用业务字段来作为主键;
2.5.2. 唯一:UNIQUE
- 某些字段在开发中是唯一的,不会重复的,比如手机号码、身份证号码等,这个字段可以使用UNIQUE来约束:
- 使用UNIQUE约束的字段在表中必须是不同的;
- 对于所有引擎,UNIQUE 索引允许NULL包含的列具有多个值NULL。
2.5.3. 不能为空:NOT NULL
某些字段要求用户必须插入值,不可以为空,这个时候可以使用 NOT NULL 来约束;
2.5.4. 默认值:DEFAULT
某些字段希望在没有设置值时给予一个默认值,这个时候可以使用 DEFAULT来完成;
2.5.5. 自动递增:AUTO_INCREMENT
某些字段希望不设置值时可以进行递增,比如用户的id,这个时候可以使用AUTO_INCREMENT来完成;
2.6. DML-数据表的操作
1 | create database if not exists test; |
2.7. DQL-数据表操作
SELECT用于从一个或者多个表中检索选中的行(Record)
查询的格式如下:
1 | SELECT select_expr [, select_expr]... [FROM table_references] |
2.7.1. 基本查询
1 | # 查询表中所有的字段以及所有的数据 |
2.7.2. 条件查询
1 | # where条件 |
2.7.3. 模糊查询
- 模糊查询使用LIKE关键字,结合两个特殊的符号:
- %表示匹配任意个的任意字符;
- _表示匹配一个的任意字符;
1 | # 模糊查询 |
2.7.4. 查询结果排序
- ORDER BY;
- ORDER BY有两个常用的值:
- ASC:升序排列;
- DESC:降序排列;
1 | # 排序 |
2.7.5. 分页查询
- 当数据库中的数据非常多时,一次性查询到所有的结果进行显示是不太现实的:
- 在真实开发中,要求传入offset、limit或者page等字段;
- 它的用法有[LIMIT {[offset,] row_count | row_count OFFSET offset}]
1 | # 分页 |
2.7.6. 聚合函数
聚合函数表示对值集合进行操作的组(集合)函数
| Name | Description |
|---|---|
AVG() |
Return the average value of the argument |
BIT_AND() |
Return bitwise AND |
BIT_OR() |
Return bitwise OR |
BIT_XOR() |
Return bitwise XOR |
COUNT() |
Return a count of the number of rows returned |
COUNT(DISTINCT) |
Return the count of a number of different values |
GROUP_CONCAT() |
Return a concatenated string |
JSON_ARRAYAGG() |
Return result set as a single JSON array |
JSON_OBJECTAGG() |
Return result set as a single JSON object |
MAX() |
Return the maximum value |
MIN() |
Return the minimum value |
STD() |
Return the population standard deviation |
STDDEV() |
Return the population standard deviation |
STDDEV_POP() |
Return the population standard deviation |
STDDEV_SAMP() |
Return the sample standard deviation |
SUM() |
Return the sum |
VAR_POP() |
Return the population standard variance |
VAR_SAMP() |
Return the sample variance |
VARIANCE() |
Return the population standard variance |
应用
1 | # 计算所有条目的数量 |
2.7.7. Group By
事实上聚合函数相当于默认将所有的数据分成了一组:
- 使用avg还是max等,都是将所有的结果看成一组来计算的;
- 那么如果希望划分多个组:比如相似名字的平均年龄值,应该怎么来做呢?
- 使用 GROUP BY;
GROUP BY通常和聚合函数一起使用
表示先对数据进行分组,再对每一组数据,进行聚合函数的计算;
给Group By查询到的结果添加一些约束,可以使用:HAVING
实现需求:
- 根据班级进行分组;
- 计算各个品牌中:人员个数、最大年龄、最小年龄、平均年龄;
- 筛选条件为平均年龄在24以上;
1 | # 添加班级列 |
2.8. 创建多张表
2.8.1. 建表
1 | create table if not exists brand( |
2.8.2. 创建外键
将两张表联系起来,将 products中的brand_id关联到brand中的id:
如果是创建表添加外键约束,我们需要在创建表的()最后添加如下语句;
1
foreign key (brand_id) references brand(id)
如果是表已经创建好,额外添加外键:
1
alter table products add foreign key(brand_id) references brand(id);
创建语句
1 | create table if not exists products( |
2.8.3. 外键存在时更新和删除数据
思考一个问题:
- 如果products中引用的外键被更新了或者删除了,这个时候会出现什么情况呢?
进行更新操作:
- 比如将华为的id更新为100
这个时候执行代码是报错的:
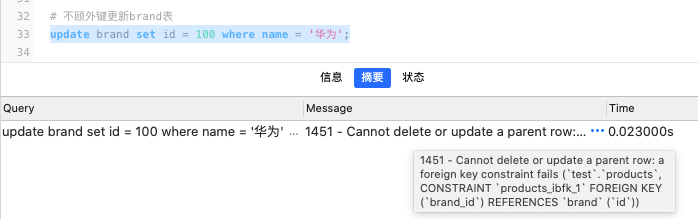
2.8.4. 如何进行更新呢?
- 修改on delete或者on update的值;
- 给更新或者删除时设置几个值:
RESTRICT(默认属性):当更新或删除某个记录时,会检查该记录是否有关联的外键记录,有的话会报错的, 不允许更新或删除;NO ACTION:和RESTRICT是一致的,是在SQL标准中定义的;CASCADE:当更新或删除某个记录时,会检查该记录是否有关联的外键记录,有的话:- 更新:那么会更新对应的记录;
- 删除:那么关联的记录会被一起删除掉;
SET NULL:当更新或删除某个记录时,会检查该记录是否有关联的外键记录,有的话,将对应的值设置为 NULL;
1 | alter table products add foreign key(brand_id) references brand(id) |
2.8.5. 多表查询
如果查询到产品的同时,显示对应的品牌相关的信息,因为数据是存放在两张表中,所以这个时候就需要进行多表查询
如果直接通过查询语句希望在多张表中查询到数据,这个时候是什么效果呢?
1
select * from products, brand;
一共有 20 条数据,这个数据量是如何得到的呢?
- 第一张表的 4 条 * 第二张表的 5 条数据;
- 也就是说第一张表中每一个条数据,都会和第二张表中的每一条数据结合一次;
- 这个结果称之为
笛卡尔乘积,也称之为直积,表示为X*Y;
但是事实上很多的数据是没有意义的,比如华为和苹果、小米的品牌结合起来的数据就是没有意义的,可不可以进行筛选呢?
使用where来进行筛选;
这个表示查询到笛卡尔乘积后的结果中,符合
products.brand_id = brand.id条件的数据过滤出来;1
2select * from products,brand
where products.brand_id = brand.id;
事实上想要的效果并不是这样的,而且表中的某些特定的数据,这个时候可以使用 SQL JOIN 操作:
- 左连接
- 右连接
- 内连接
- 全连接
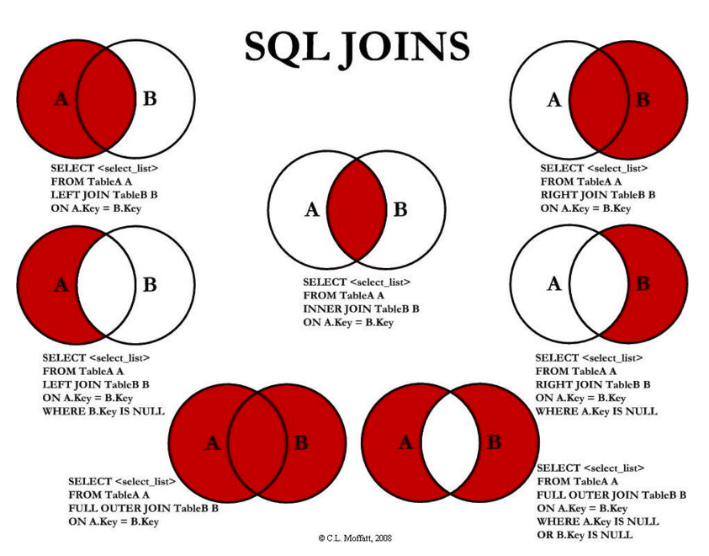
2.8.6. 左连接
如果希望获取到的是左边所有的数据(以左表为主):
这个时候就表示无论左边的表是否有对应的brand_id的值对应右边表的id,左边的数据都会被查询出来;
这个也是开发中使用最多的情况,它的完整写法是LEFT [OUTER] JOIN,但是OUTER可以省略的;
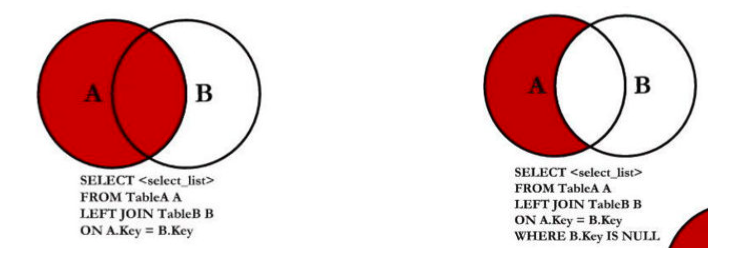
1
2
3
4
5
6
7
8
9
10
11# 左连接
# 查询所有的手机(包括没有品牌信息的手机)以及对应的品牌null
select * from products
left join brand
on products.brand_id = brand.id;
# 查询没有对应品牌数据的手机
select * from products
left join brand
on products.brand_id = brand.id
where brand.id is null;
2.8.7. 右连接
如果希望获取到的是右边所有的数据(以由表为主):
这个时候就表示无论左边的表中的brand_id是否有和右边表中的id对应,右边的数据都会被查询出来;
右连接在开发中没有左连接常用,它的完整写法是RIGHT [OUTER] JOIN,但是OUTER可以省略的;

1
2
3
4
5
6
7
8
9
10
11# 右连接
# 查询所有的品牌(包括没有手机信息的品牌)以及对应的手机null
select * from products
right join brand
on products.brand_id = brand.id;
# 查询没有对应手机数据的品牌
select * from products
right join brand
on products.brand_id = brand.id
where products.brand_id is null;
2.8.8. 内连接
事实上内连接是表示左边的表和右边的表都有对应的数据关联:
内连接在开发中偶尔也会常见使用;
内连接有其他的写法:CROSS JOIN或者 JOIN都可以;
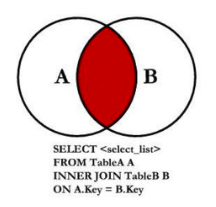
1
2
3select * from products
inner join brand
on products.brand_id = brand.id;它和之前的下面写法是一样的效果:
1
select * from products,brand where products.brand_id = brand.id;
但是他们代表的含义并不相同:
- SQL语句一:内连接,代表的是在两张表连接时就会约束数据之间的关系,来决定之后查询的结果;
- SQL语句二:where条件,代表的是先计算出笛卡尔乘积,在笛卡尔乘积的数据基础之上进行where条件的筛选;
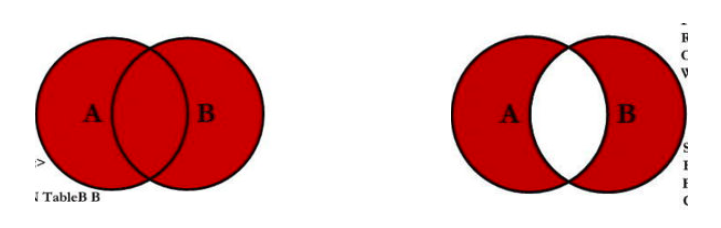
2.8.9. 全连接
SQL规范中全连接是使用FULL JOIN,但是MySQL中并没有对它的支持,我们需要使用 UNION 来实现:
1 | (select * from products left join brand on products.brand_id = brand.id) |
2.9. 多对多关系数据
- 在开发中遇到多对多的关系:
- 比如学生可以选择多门课程,一个课程可以被多个学生选择;
- 这种情况应该在开发中如何处理呢?
2.9.1. 建立两张表
1 | # 创建学生表 |
2.9.2. 创建关系表
1 | # 关系表 |
2.9.3. 查询多对多数据
1 | # 查询所有的学生选择的所有课程 |
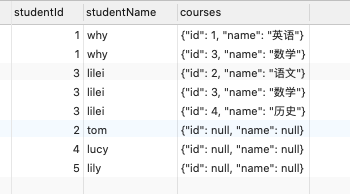
2.10. 将联合查询到的数据转成对象
1 | # 将联合查询到的数据转成对象 |
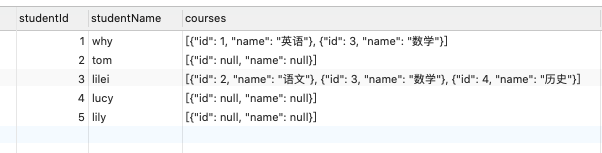
2.11. 将联合查询到的数据转成数组
- 在多对多关系中,希望查询到的是一个数组:
- 比如一个学生的多门课程信息,应该是放到一个数组中的;
- 数组中存放的是课程信息的一个个对象;
- 这个时候要 JSON_ARRAYAGG和JSON_OBJECT结合来使用;
1 | select |
3. node操作数据库
3.1. 认识mysql2
https://github.com/sidorares/node-mysql2
- 如何在Node的代码中执行SQL语句来,这里可以借助于两个库:
- mysql:最早的Node连接MySQL的数据库驱动;
- mysql2:在mysql的基础之上,进行了很多的优化、改进;
- 目前相对来说,更偏向于使用mysql2,mysql2兼容mysql的API,并且提供了一些附加功能
- 更快/更好的性能;
- Prepared Statement(预编译语句):
- 提高性能:将创建的语句模块发送给MySQL,然后MySQL编译(解析、优化、转换)语句模块,并且存储它,但是不执行,在真正执行时会提供实际的参数才会执行;就算多次执行,也只会编译一次,所以性能是更高的;
- 防止SQL注入:之后传入的值不会像模块引擎那样就编译,那么一些SQL注入的内容不会被执行;or 1 = 1不会被执行;
- 支持Promise,所以我们可以使用async和await语法
- ….
3.2. 使用mysql2
安装mysql2
1
npm i mysql2
mysql2的使用过程如下
- 创建连接(通过createConnection),并且获取连接对象;
- 执行SQL语句即可(通过query);
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20const mysql = require("mysql2");
// 1. 创建数据库连接
const connection = mysql.createConnection({
host: 'localhost',
port: 3306,
database: 'test',
user: 'root',
password: '密码'
});
// 2. 执行sql语句
const statement = 'select * from user';
connection.query(statement,(err,result,fields)=>{
console.log(err);
console.log(result);
console.log(fields);
// 关闭数据库连接
connection.destroy();
});
3.2.1. Prepared Statement
Prepared Statement(预编译语句)
- 提高性能:将创建的语句模块发送给MySQL,然后MySQL编译(解析、优化、转换)语句模块,并且存储它,但是不执行,在真正执行时会提供实际的参数才会执行;就算多次执行,也只会编译一次,所以性能是更高的;
- 防止SQL注入:之后传入的值不会像模块引擎那样就编译,那么一些SQL注入的内容不会被执行;or 1 = 1不会被执行;
如果再次执行该语句,它将会从LRU(Least Recently Used) Cache中获取获取,省略了编译statement 的时间来提高性能
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17const mysql = require("mysql2");
// 1. 创建数据库连接
const connection = mysql.createConnection({
host: 'localhost',
port: 3306,
database: 'test',
user: 'root',
password: '密码'
});
// 2. 执行sql语句
// Prepared Statement
const sql = 'select * from user where age > ? and name like "%a%"';
connection.execute(sql,[18],(err,result)=>{
console.log(result);
});
3.2.2. Connection Pools
- 如果有多个请求的话,该连接很有可能正在被占用,那么是否需要每次一个请求都去创建一个新的连接呢?
- 事实上,mysql2给我们提供了连接池(connection pools);
- 连接池可以在需要的时候自动创建连接,并且创建的连接不会被销毁,会放到连接池中,后续可以继续使用;
- 在创建连接池的时候设置LIMIT,也就是最大创建个数;
1 | const connection = mysql.createPool({ |
3.2.3. Promise方式
1 | const mysql = require("mysql2"); |
3.3. 认识ORM
对象关系映射(英语:Object Relational Mapping,简称ORM,或O/RM,或O/R mapping),是一种程序设计的方案:
- 从效果上来讲,它提供了一个可在编程语言中,使用虚拟对象数据库 的效果;
- 比如在Java开发中经常使用的ORM包括:
Hibernate、MyBatis;
Node当中的ORM通常使用的是
sequelize;- Sequelize是用于Postgres,MySQL,MariaDB,SQLite和Microsoft SQL Server的基于Node.js 的 ORM;
- 它支持非常多的功能;
如果希望将Sequelize和MySQL一起使用,那么需要先安装两个东西:
mysql2:sequelize在操作mysql时使用的是mysql2;
sequelize:使用它来让对象映射到表中;
1
npm install sequelize
3.3.1. Sequelize的使用
https://github.com/sequelize/sequelize/
https://sequelize.org/docs/v6/getting-started/
创建一个Sequelize的对象,并且指定数据库、用户名、密码、数据库类型、主机地址等;
测试连接是否成功;
1 | const {Sequelize,DataTypes} = require("sequelize"); |
3.3.2. Sequelize映射关系表
https://sequelize.org/docs/v6/core-concepts/model-basics/
1 | const {Sequelize,DataTypes,Model,Op} = require("sequelize"); |
3.3.3. 一对多操作
1 | // 多表映射 |
转换的语句
1 | Executing (default): SELECT `Products`.`id`, `Products`.`brand`, `Products`.`brand_id` AS `brandId`, `Brand`.`id` AS `Brand.id`, `Brand`.`name` AS `Brand.name`, `Brand`.`website` AS `Brand.website`, `Brand`.`worldRank` AS `Brand.worldRank` FROM `products` AS `Products` LEFT OUTER JOIN `brand` AS `Brand` ON `Products`.`brand_id` = `Brand`.`id`; |
3.3.4. 多对多操作
1 | // 多表映射 |
转换的语句
1 | Executing (default): SELECT `Student`.`id`, `Student`.`student_id` AS `studentId`, `Student`.`course_id` AS `courseId`, `Courses`.`id` AS `Courses.id`, `Courses`.`name` AS `Courses.name`, `Courses->students_select_courses`.`student_id` AS `Courses.students_select_courses.student_id`, `Courses->students_select_courses`.`course_id` AS `Courses.students_select_courses.course_id` FROM `students_select_courses` AS `Student` LEFT OUTER JOIN ( `students_select_courses` AS `Courses->students_select_courses` INNER JOIN `courses` AS `Courses` ON `Courses`.`id` = `Courses->students_select_courses`.`course_id`) ON `Student`.`id` = `Courses->students_select_courses`.`student_id`; |