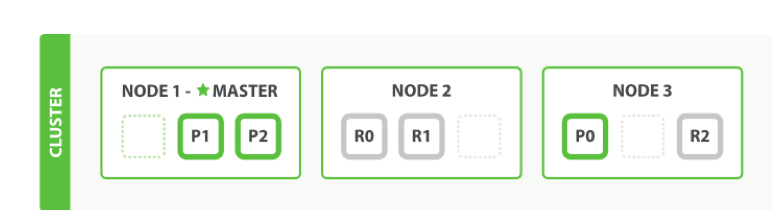
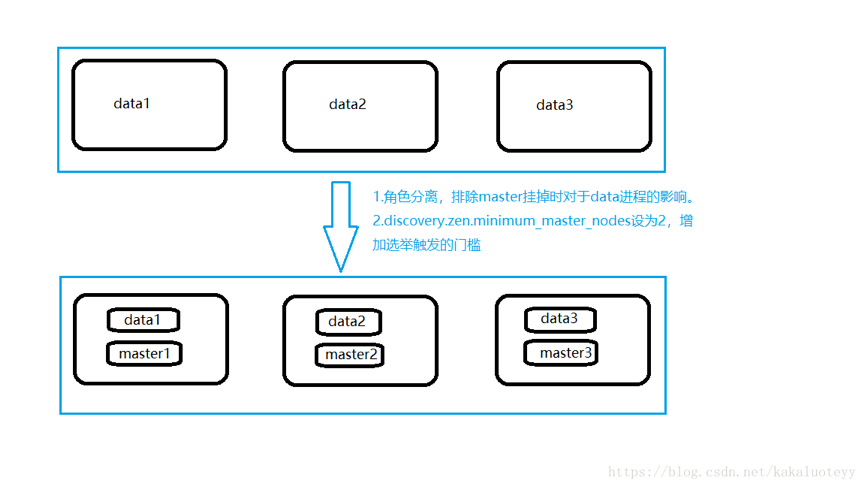
# Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1): # 如果没有这种设置,遭受网络故障的集群就有可能将集群分成两个独立的集群 – 导致脑裂 - 这将导致数据丢失 discovery.zen.minimum_master_nodes:2
customer 1 p STARTED 0162b 172.17.0.4101-es2 customer 1 r STARTED 0162b 172.17.0.2101-es1 customer 3 r STARTED 13.3kb 172.17.0.5101-es3 customer 3 p STARTED 13.3kb 172.17.0.2101-es1 customer 4 p STARTED 0162b 172.17.0.4101-es2 customer 4 r STARTED 0162b 172.17.0.2101-es1 customer 2 r STARTED 0162b 172.17.0.4101-es2 customer 2 p STARTED 0162b 172.17.0.5101-es3 customer 0 r STARTED 0162b 172.17.0.5101-es3 customer 0 p STARTED 0162b 172.17.0.2101-es1 .kibana 0 p STARTED 13.2kb 172.17.0.4101-es2 .kibana 0 r STARTED 13.2kb 172.17.0.5101-es3
GET _cat/master xWuBdPbpSMqkCCbIfY07Mg 172.17.0.2172.17.0.2101-es1
GET /_cat/shards
customer 1 p STARTED 0162b 172.17.0.2101-es1 customer 1 r UNASSIGNED customer 3 r STARTED 13.4kb 172.17.0.5101-es3 customer 3 p STARTED 13.4kb 172.17.0.2101-es1 customer 4 p STARTED 0162b 172.17.0.2101-es1 customer 4 r UNASSIGNED customer 2 p STARTED 0162b 172.17.0.5101-es3 customer 2 r UNASSIGNED customer 0 r STARTED 0162b 172.17.0.5101-es3 customer 0 p STARTED 0162b 172.17.0.2101-es1 .kibana 0 p STARTED 13.2kb 172.17.0.5101-es3 .kibana 0 r UNASSIGNED
#重新分配 customer 1 r STARTED 0162b 172.17.0.5101-es3 customer 1 p STARTED 0162b 172.17.0.2101-es1 customer 3 r STARTED 13.4kb 172.17.0.5101-es3 customer 3 p STARTED 13.4kb 172.17.0.2101-es1 customer 4 r STARTED 0162b 172.17.0.5101-es3 customer 4 p STARTED 0162b 172.17.0.2101-es1 customer 2 p STARTED 0162b 172.17.0.5101-es3 customer 2 r STARTED 0162b 172.17.0.2101-es1 customer 0 r STARTED 0162b 172.17.0.5101-es3 customer 0 p STARTED 0162b 172.17.0.2101-es1 .kibana 0 p STARTED 13.2kb 172.17.0.5101-es3 .kibana 0 r STARTED 13.2kb 172.17.0.2101-es1
# Kibana is served by a back end server. This setting specifies the port to use. #server.port: 5601 # Specifies the address to which the Kibana server will bind. IP addresses and host names are both valid values. # The default is 'localhost', which usually means remote machines will not be able to connect. # To allow connections from remote users, set this parameter to a non-loopback address. #server.host: "localhost" # Enables you to specify a path to mount Kibana at if you are running behind a proxy. This only affects # the URLs generated by Kibana, your proxy is expected to remove the basePath value before forwarding requests # to Kibana. This setting cannot end in a slash. #server.basePath: "" # The maximum payload size in bytes for incoming server requests. #server.maxPayloadBytes: 1048576 # The Kibana server's name. This is used for display purposes. #server.name: "your-hostname" # The URL of the Elasticsearch instance to use for all your queries. #elasticsearch.url: "http://localhost:9200" # When this setting's value is true Kibana uses the hostname specified in the server.host # setting. When the value of this setting is false, Kibana uses the hostname of the host # that connects to this Kibana instance. #elasticsearch.preserveHost: true # Kibana uses an index in Elasticsearch to store saved searches, visualizations and # dashboards. Kibana creates a new index if the index doesn't already exist. #kibana.index: ".kibana" # The default application to load. #kibana.defaultAppId: "discover" # If your Elasticsearch is protected with basic authentication, these settings provide # the username and password that the Kibana server uses to perform maintenance on the Kibana # index at startup. Your Kibana users still need to authenticate with Elasticsearch, which # is proxied through the Kibana server. #elasticsearch.username: "user" #elasticsearch.password: "pass" # Enables SSL and paths to the PEM-format SSL certificate and SSL key files, respectively. # These settings enable SSL for outgoing requests from the Kibana server to the browser. #server.ssl.enabled: false #server.ssl.certificate: /path/to/your/server.crt #server.ssl.key: /path/to/your/server.key # Optional settings that provide the paths to the PEM-format SSL certificate and key files. # These files validate that your Elasticsearch backend uses the same key files. #elasticsearch.ssl.certificate: /path/to/your/client.crt #elasticsearch.ssl.key: /path/to/your/client.key # Optional setting that enables you to specify a path to the PEM file for the certificate # authority for your Elasticsearch instance. #elasticsearch.ssl.certificateAuthorities: [ "/path/to/your/CA.pem" ] # To disregard the validity of SSL certificates, change this setting's value to 'none'. #elasticsearch.ssl.verificationMode: full # Time in milliseconds to waitfor Elasticsearch to respond to pings. Defaults to the value of # the elasticsearch.requestTimeout setting. #elasticsearch.pingTimeout: 1500 # Time in milliseconds to waitfor responses from the back end or Elasticsearch. This value # must be a positive integer. #elasticsearch.requestTimeout: 30000 # List of Kibana client-side headers to send to Elasticsearch. To send *no* client-side # headers, set this value to [] (an empty list). #elasticsearch.requestHeadersWhitelist: [ authorization ] # Header names and values that are sent to Elasticsearch. Any custom headers cannot be overwritten # by client-side headers, regardless of the elasticsearch.requestHeadersWhitelist configuration. #elasticsearch.customHeaders: {} # Time in milliseconds for Elasticsearch to waitfor responses from shards. Set to 0 to disable. #elasticsearch.shardTimeout: 0 # Time in milliseconds to waitfor Elasticsearch at Kibana startup before retrying. #elasticsearch.startupTimeout: 5000 # Specifies the path where Kibana creates the process ID file. #pid.file: /var/run/kibana.pid # Enables you specify a file where Kibana stores log output. #logging.dest: stdout # Set the value of this setting to true to suppress all logging output. #logging.silent: false # Set the value of this setting to true to suppress all logging output other than error messages. #logging.quiet: false # Set the value of this setting to true to log all events, including system usage information # and all requests. #logging.verbose: false # Set the interval in milliseconds to sample system and process performance # metrics. Minimum is 100ms. Defaults to 5000. #ops.interval: 5000 # The default locale. This locale can be used in certain circumstances to substitute any missing # translations. #i18n.defaultLocale: "en"
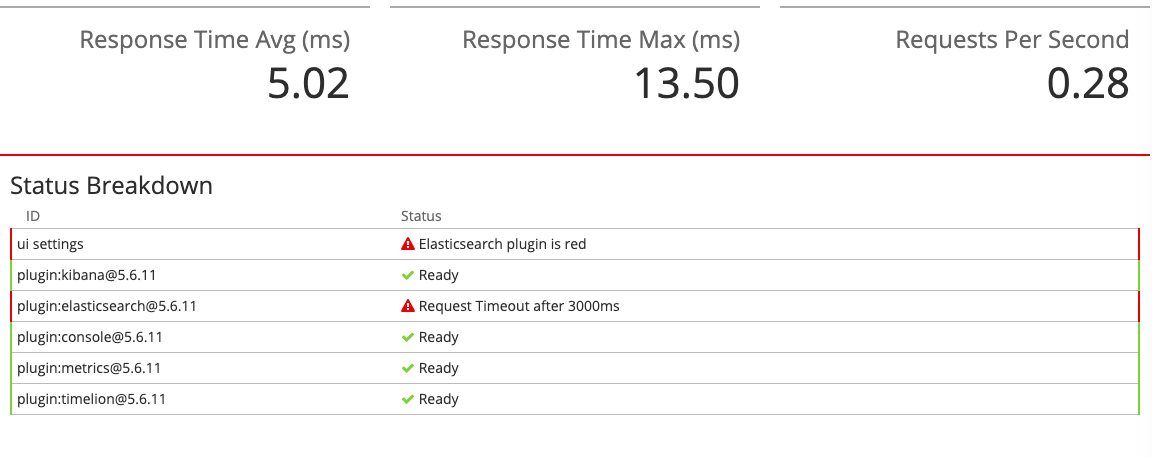
[root@192 config]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 7122d84209e4 kibana:5.6.11 "/docker-entrypoint.…" 25 minutes ago Up 10 minutes 0.0.0.0:5601->5601/tcp kibana 760ba5e8259c elasticsearch:5.6.11 "/docker-entrypoint.…" About an hour ago Up 49 minutes 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp elasticsearch [root@192 config]# [root@192 config]# [root@192 config]# docker logs 7122d84209e4 "tags":["status","ui settings","info"],"pid":9,"state":"green","message":"Status changed from yellow to green - Ready","prevState":"yellow","prevMsg":"Elasticsearch plugin is yellow"}
cluster.name: es-linux # # ------------------------------------ Node ------------------------------------ # # Use a descriptive name for the node: # node.name: node-linux # # Add custom attributes to the node: # # node.attr.rack: r1 # # ----------------------------------- Paths ------------------------------------ # # Path to directory where to store the data (separate multiple locations by comma): # path.data: /usr/local/elasticsearch-7.6.1/data # # Path to log files: # path.logs: /usr/local/elasticsearch-7.6.1/logs # # ----------------------------------- Memory ----------------------------------- # # Lock the memory on startup: # bootstrap.memory_lock: false bootstrap.system_call_filter: false # ---------------------------------- Network ----------------------------------- # # Set the bind address to a specific IP (IPv4 or IPv6): # network.host: 0.0.0.0 # # Set a custom port for HTTP: # http.port: 9200 # # --------------------------------- Discovery ---------------------------------- # # Pass an initial list of hosts to perform discovery when this node is started: # The default list of hosts is ["127.0.0.1", "[::1]"] # discovery.zen.ping.unicast.hosts: ["127.0.0.1","192.168.0.100","192.168.0.112"] # # Bootstrap the cluster using an initial set of master-eligible nodes: # cluster.initial_master_nodes: ["es-linux"] # # For more information, consult the discovery and cluster formation module documentation. #
ERROR Unable to invoke factory method in class org.apache.logging.log4j.core.appender.RollingFileAppender for element RollingFile
1
[root@192 bin]# yum install -y log4j
max file descriptors [4096] for elasticsearch process likely too low, increase to at least [65536]
1 2 3 4 5 6
[root@192 bin]# nano /etc/security/limits.conf
* soft nofile 65536 * hard nofile 65536 * soft nproc 4096 * hard nproc 4096
max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
1 2 3 4 5
nano /etc/sysctl.conf
vm.max_map_count=262144
sysctl -p
运行
1 2
[root@192 bin]# su elasticsearch [elasticsearch@192 bin]$ ./elasticsearch
future versions of Elasticsearch will require Java 11; 运行es自带jdk
注释原有java_home的判断
1 2 3 4 5 6 7 8 9 10 11 12 13 14
vi elasticsearch-env
#if [ ! -z "$JAVA_HOME" ]; then # JAVA="$JAVA_HOME/bin/java" # JAVA_TYPE="JAVA_HOME" #else if [ "$(uname -s)" = "Darwin" ]; then # macOS has a different structure JAVA="$ES_HOME/jdk.app/Contents/Home/bin/java" else JAVA="$ES_HOME/jdk/bin/java" fi JAVA_TYPE="bundled jdk" #fi
server.port: 5601 # To allow connections from remote users server.host: "192.168.0.100" # The URLs of the Elasticsearch instances to use for all your queries. elasticsearch.hosts: ["http://192.168.0.100:9200"]
root@pi:/usr/local/jffi# cd /usr/local/logstash/vendor/jruby/lib/jni/arm-Linux root@pi:/usr/local/logstash/vendor/jruby/lib/jni/arm-Linux# ls libjffi-1.2.so root@pi:/usr/local/logstash/vendor/jruby/lib/jni/arm-Linux# cd /usr/local/jffi/build/jni/ root@pi:/usr/local/jffi/build/jni# ls com_kenai_jffi_Foreign.h com_kenai_jffi_Foreign_InValidInstanceHolder.h com_kenai_jffi_ObjectBuffer.h jffi libjffi-1.2.so com_kenai_jffi_Foreign_InstanceHolder.h com_kenai_jffi_Foreign_ValidInstanceHolder.h com_kenai_jffi_Version.h libffi-arm-linux root@pi:/usr/local/jffi/build/jni# cd /usr/local/logstash/vendor/jruby/lib/jni/arm-Linux root@pi:/usr/local/logstash/vendor/jruby/lib/jni/arm-Linux# mv libjffi-1.2.so libjffi-1.2.so.old root@pi:/usr/local/logstash/vendor/jruby/lib/jni/arm-Linux# cd /usr/local/jffi/build/jni/ root@pi:/usr/local/jffi/build/jni# cp libjffi-1.2.so /usr/local/logstash/vendor/jruby/lib/jni/arm-Linux/libjffi-1.2.so root@pi:/usr/local/jffi/build/jni# cd /usr/local/logstash/vendor/jruby/lib/jni/arm-Linux root@pi:/usr/local/logstash/vendor/jruby/lib/jni/arm-Linux# ls libjffi-1.2.so libjffi-1.2.so.old root@pi:/usr/local/logstash/vendor/jruby/lib/jni/arm-Linux# root@pi:/usr/local/logstash/vendor/jruby/lib/jni/arm-Linux# root@pi:/usr/local/logstash/vendor/jruby/lib/jni/arm-Linux# root@pi:/usr/local/logstash/vendor/jruby/lib/jni/arm-Linux# cd /usr/local/logstash/bin root@pi:/usr/local/logstash/bin# ./logstash io/console not supported; tty will not be manipulated No command given
Usage: logstash <command> [command args] Run a command with the --help flag to see the arguments. For example: logstash agent --help
Available commands: agent - runs the logstash agent version - emits version info about this logstash root@pi:/usr/local/logstash/bin# ls logstash logstash.bat logstash.lib.sh plugin plugin.bat rspec rspec.bat setup.bat root@pi:/usr/local/logstash/bin# logstash bash: logstash:未找到命令 root@pi:/usr/local/logstash/bin# ./logstash --help io/console not supported; tty will not be manipulated Usage: /bin/logstash agent [OPTIONS]
Options: -f, --config CONFIG_PATH Load the logstash config from a specific file or directory. If a directory is given, all files in that directory will be concatenated in lexicographical order and then parsed as a single config file. You can also specify wildcards (globs) and any matched files will be loaded in the order described above. -e CONFIG_STRING Use the given string as the configuration data. Same syntax as the config file. If no input is specified, then the following is used as the default input: "input { stdin { type => stdin } }" and if no output is specified, then the following is used as the default output: "output { stdout { codec => rubydebug } }" If you wish to use both defaults, please use the empty string for the '-e' flag. (default: "") -w, --filterworkers COUNT Sets the number of filter workers to run. (default: 2) -l, --log FILE Write logstash internal logs to the given file. Without this flag, logstash will emit logs to standard output. -v Increase verbosity of logstash internal logs. Specifying once will show 'informational' logs. Specifying twice will show 'debug' logs. This flag is deprecated. You should use --verbose or --debug instead. --quiet Quieter logstash logging. This causes only errors to be emitted. --verbose More verbose logging. This causes 'info' level logs to be emitted. --debug Most verbose logging. This causes 'debug' level logs to be emitted. -V, --version Emit the version of logstash and its friends, then exit. -p, --pluginpath PATH A path of where to find plugins. This flag can be given multiple times to include multiple paths. Plugins are expected to be in a specific directory hierarchy: 'PATH/logstash/TYPE/NAME.rb' where TYPE is 'inputs' 'filters', 'outputs' or 'codecs' and NAME is the name of the plugin. -t, --configtest Check configuration for valid syntax and then exit. -h, --help print help root@pi:/usr/local/logstash/bin#
运行logstash脚本
1 2 3 4 5 6 7 8 9 10 11
root@pi:/usr/local/logstash/bin# ./logstash -e 'input{stdin{}}output{stdout{codec=>rubydebug}}' io/console not supported; tty will not be manipulated Default settings used: Filter workers: 2 Logstash startup completed Hello World { "message" => "Hello World", "@version" => "1", "@timestamp" => "2020-03-29T08:28:52.594Z", "host" => "pi" }
 )
)