数据结构三要素,时间复杂度,空间复杂度
1. 数据结构在学什么?
如何用程序代码把现实世界的问题信息化
人类社会的发展,迄今经历了和经历着三个浪潮:第一次浪潮为农业阶段,从约1万年前开始;第二次浪潮为工业阶段,从17世纪末开始;第三次浪潮为正在到来的信息化阶段。—《第三次浪潮(1980版)》,阿尔文·托夫勒
金钱:纸币->支付宝余额,微信余额
买饭:排队->在线点菜
交友:面对面交流->微信,QQ
如何在计算机中表示这些信息???
金额:浮点型变量(float)
取号:队列
微博关注:图,树
如何用计算机高效地处理这些信息从而创造价值
唯一可以确定的是,明天会使我们所有人大吃一惊。 —— 阿尔文·托夫勒 (The sole certainty is that tomorrow will surprise us all.)
人类文明 :
农业革命【学会农耕,从“动物” 到“人类”】
工业革命【出现枪炮与机械,导致古文明灭亡】
信息革命【高度信息化的世界,导致???】
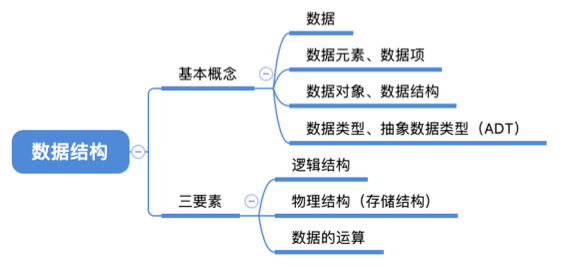
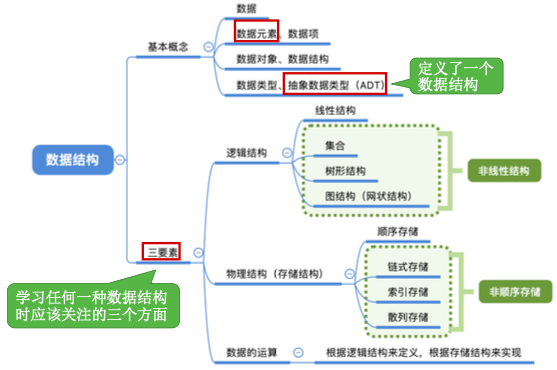
2. 数据结构基本概念
2.1. 知识总览
2.2. 什么是数据?
画家用画笔描述世界
音乐家用音符描述世界
计算机专业人员用数据描述世界
数据: 数据是信息的载体,是描述客观事物属性的数、字符及所有能输入到计算机中并被计算机程序识别(二进制0/1)和处理的符号的集合。数据是计算机程序加工的原料。
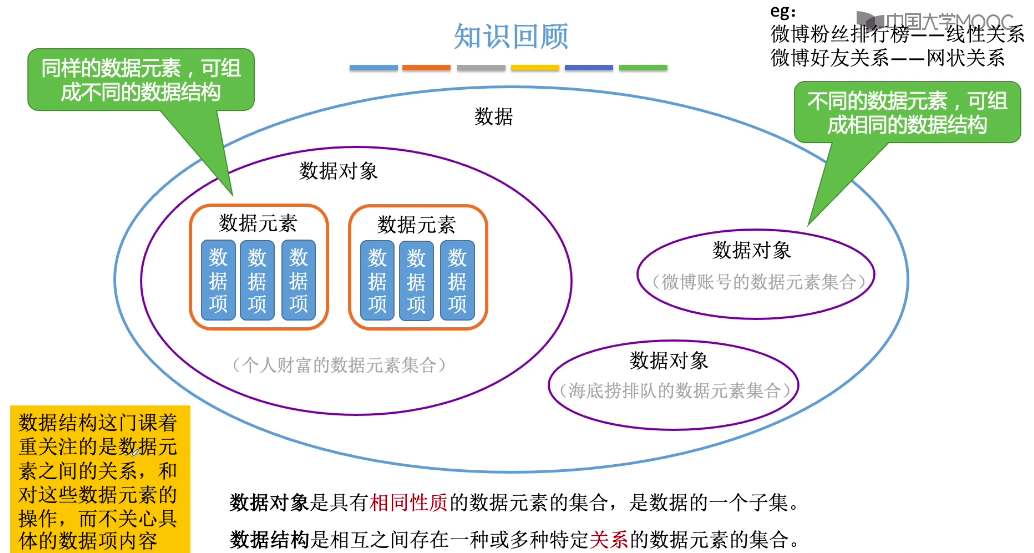
同样的数据对象里的数据元素可以组成不同的数据结构
个人财富数据,排行榜可以组成线性结构,也可以组成名人朋友圈
不同的数据对象里的数据元素可以组成相同的数据结构
微博账号的粉丝排行榜可以组成线性结构,个人财富排行榜也可以组成线性结构
微博好友关系可以组成网状结构,个人财富数据也可以组成名人朋友圈
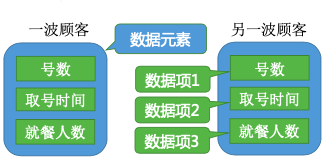
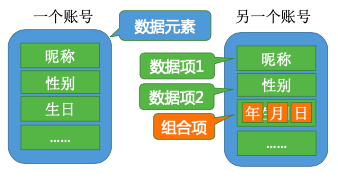
2.3. 数据元素(个体)、数据项(个体特征)
数据元素是数据的基本单位,通常作为一个整体进行考虑和处理。 一个数据元素可由若干数据项组成,数据项是构成数据元素的不可分割的最小单位。
要根据实际的业务需求来确定什么是数据元素、什么是数据项
2.4. 数据结构、数据对象
结构-各个元素之间的关系
沙- 左右结构,粥- 左中右结构,曼- 上中下结构
数据结构是相互之间存在一种或多种特定关系的数据元素的集合。
数据对象是具有相同性质的数据元素的集合,是数据的一个子集。
例如:
数据结构:某个特定门店的排队顾客信息和它们之间的关系
数据对象:全国所有门店的排队顾客信息
2.5. 数据结构的三要素
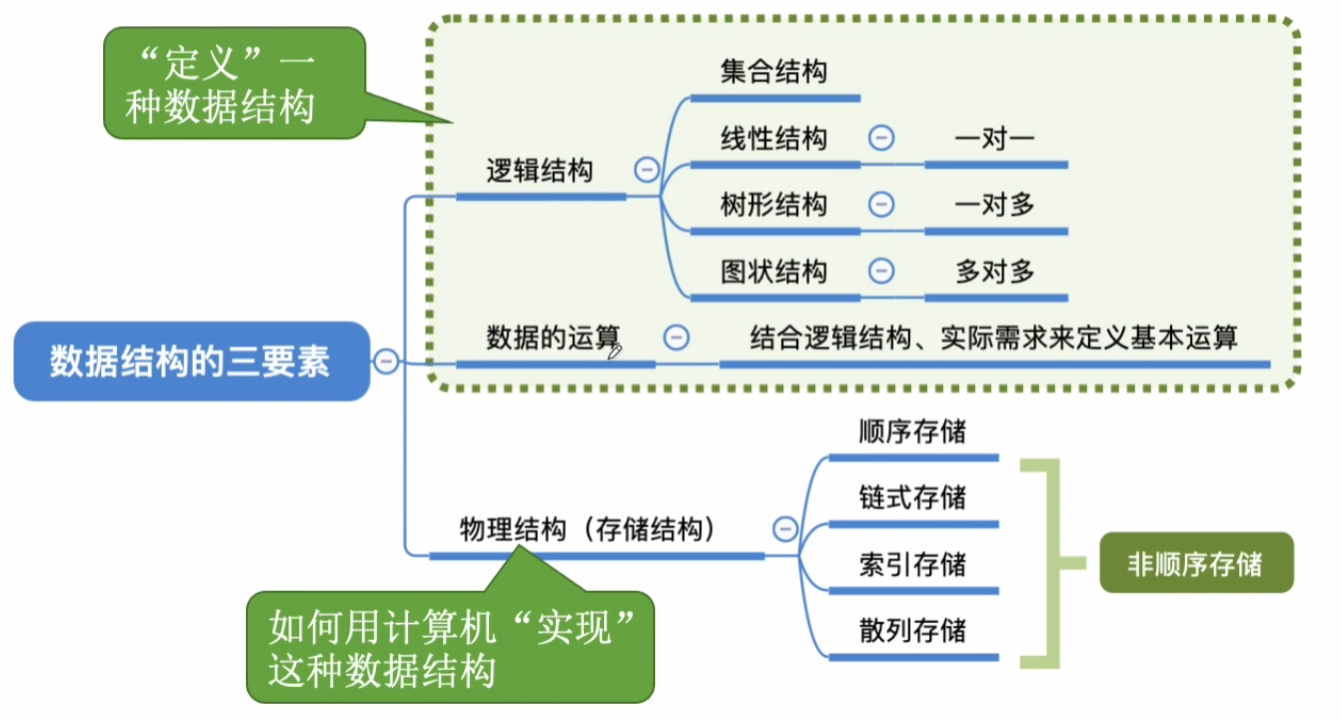
2.5.1. 逻辑结构-定义数据结构
数据元素之间的逻辑关系
2.5.1.1. 集合
各个元素同属一个集合,别无其他关系
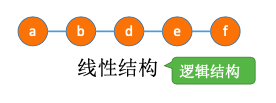
2.5.1.2. 线性结构
数据元素之间是一对一的关系。 除了第一个元素,所有元素都有唯一前驱; 除了最后一个元素,所有元素都有唯一后继
2.5.1.3. 树形结构
数据元素之间是一对多的关系
2.5.1.4. 图状结构
数据元素之间是多对多的关系
2.5.2. 存储结构-实现数据结构
如何用计算机表示数据元素的逻辑关系
确定一种存储结构,就意味着在计算机中表示出数据的逻辑结构。
存储结构不同,也会导致运算的具体实现不同。 确定了存储结构,才能实现数据结构
理解两点:
若采用顺序存储,则各个数据元素在物理上必须是连续的;若采用非顺序存储,则各个数据元素在物理上可以是离散的。
数据的存储结构会影响存储空间分配的方便程度(有人想插队),数据的存储结构会影响对数据运算的速度(找第三个人)
2.5.2.1. 顺序结构
把逻辑上相邻的元素存储在物理位置上也相邻的存储单元中,元素之间的关系由存储单元的邻接关系来体现。优点是可以实现随机存取,每个元素占用最少的存储空间;缺点是只能使用相邻的一整块存储单元,因此可能产生较多的外部碎片。
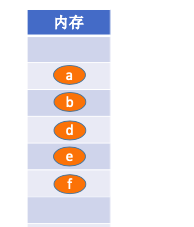
2.5.2.2. 链式结构
逻辑上相邻的元素在物理位置上可以不相邻,借助指示元素存储地址的指针来表示元素之间的逻辑关系。优点是不会出现碎片现象,能充分利用所有存储单元。缺点是不支持随机存取,每个元素因存储指针而占用额外的存储空间。
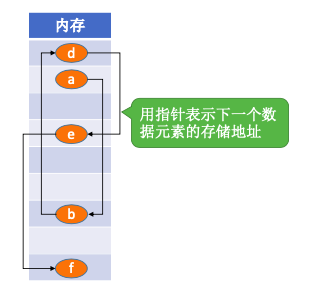
2.5.2.3. 索引结构
在存储元素信息的同时,还建立附加的索引表。索引表中的每项称为索引项,索引项 的一般形式是(关键字,地址)。优点是检索速度快;缺点是附加索引表额外占用存储空间。增加和删除需要修改索引表而花费更多的时间。
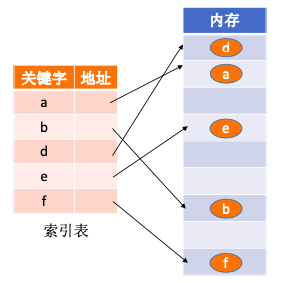
2.5.2.4. 散列结构
根据元素的关键字直接计算出该元素的存储地址,又称哈希(Hash)存储。优点是检索,增加和删除结点的操作很快;缺点是若散列函数不好,可能出现元素存储单元的冲突,而解决冲突会增加时间和空间复杂度。
2.5.3. 数据的运算
施加在数据上的运算包括运算的定义和实现。
运算的定义是针对逻辑结构的, 指出运算的功能;
运算的实现是针对存储结构的,指出运算的具体操作步骤。
逻辑结构——线性结构(队列)
结合现实需求定义队列这种逻辑结构的运算:
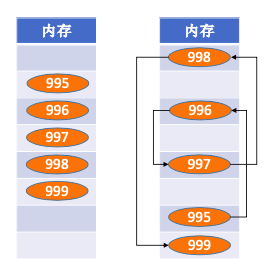
995-996-997-998
- 队头元素出队; 叫995
- 新元素入队; 取999
- 输出队列长度;
运算实现取999号,顺序结构和链式结构不同:
2.6. 数据类型、抽象数据类型
数据类型是一个值的集合和定义在此集合上的一组操作的总称。
原子类型。其值不可再分的数据类型。
bool 类型:
值的范围:true、false
可进⾏的操作:与、或、非…
int 类型
值的范围:-2147483648 ~ 2147483647
可进⾏的操作:加、减、乘、除、模运算…
结构类型。其值可以再分解为若干成分(分量)的数据类型。
1
2
3
4
5
6
7
8
9//定义一个具体的结构类型,表示排队顾客信息。
//根据具体业务需求来确定值的范围,可进行的操作
struct Customer{
//值的范围:num(1~9999)、people(1~12)
//可进行操作:如“拼桌”运算,把人数相加合并
int num; //号数
int people; //人数
...... //其他必要的信息
};抽象数据类型(Abstract Data Type,ADT)是抽象数据组织及与之相关的操作。用数学化的语言定义数据的逻辑结构、定义运算。 与具体的实现无关。
通常用【数据对象,数据关系,基本操作集】三元组来表示。
定义一个ADT,就是定义了数据的逻辑结构、数据的运算。 也就是定义了一个数据结构。
2.7. 总结
在探讨一种数据结构时:
- 定义逻辑结构(数据元素之间的关系)
- 定义数据的运算(针对现实需求,应该对这种逻辑结构进行什么样的运算)
- 确定某种存储结构,实现数据结构,并实现一些对数据结构的基本运算
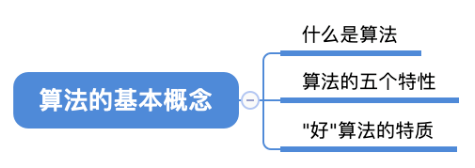
3. 算法基本概念
3.1. 总览
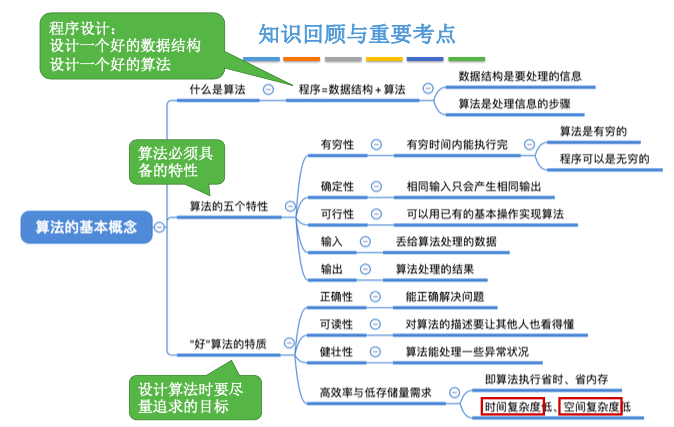
3.2. 什么是算法?
程序 = 数据结构 + 算法
数据结构:如何把现实世界的问题信息化,将信息存进计算机。同时还要如何处理这些信息,以实现对数据结构的基本操作
算法:如何处理这些信息,以解决实际问题
| 海底捞排队系统的数据结构——队列 | 要解决的现实问题——带小孩的顾客优先就餐 |
|---|---|
| 已经实现的基本操作: 1. 队头元素出队; 2. 新元素入队; 3. 输出队列长度; 4. 交换第 i 号和第 j 号的位置 |
设计一个算法: - 执行基本操作2(新顾客取号) - 依次对比前一桌信息,如果前一桌没有小孩, 则使用基本操作4交换位置。 |
3.3. 算法的特性
3.3.1. 有穷性
一个算法必须总在执行有穷步之后结束,且每一步都可在有穷时间内完成。
算法必须是有穷的,而程序可以是无穷的
算法:用有限步骤解决某个特定的问题
程序:海底捞的排队系统就是一个程序,可以永不停歇
设计一个算法,解决一个特定的问题——带小孩的顾客优先就餐
3.3.2. 确定性
算法中每条指令必须有确切的含义,对于相同的输入只能得出相同的输出。
3.3.3. 可行性
算法中描述的操作都可以通过已经实现的基本运算执行有限次来实现。
3.3.4. 输入
一个算法有零个或多个输入,这些输入取自于某个特定的对象的集合。
3.3.5. 输出
一个算法有一个或多个输出,这些输出是与输入有着某种特定关系的量。
3.4. “好”算法的特质
设计算法时要尽量追求的目标
3.4.1. 正确性
算法应能够正确地解决求解问题
3.4.2. 可读性
算法应具有良好的可读性,以帮助人们理解。
算法可以用伪代码描述,甚至用文字描述, 重要的是要“无歧义”地描述出解决问题的步骤
3.4.3. 健壮性
输入非法数据时,算法能适当地做出反应或进行处理,而不会产生莫名其妙的输出结果。
3.4.4. 高效率与低存储量需求
执行速度快。 时间复杂度低
不费内存。 空间复杂度低
3.5. 总结
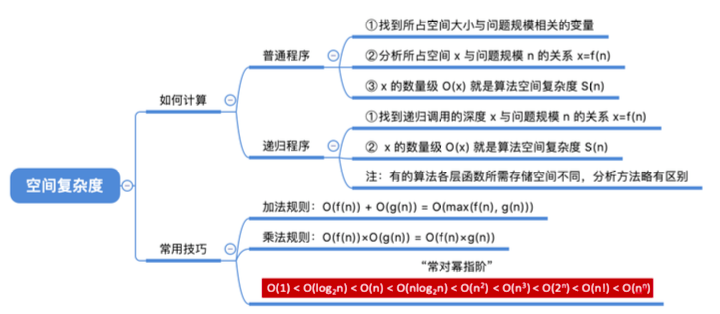
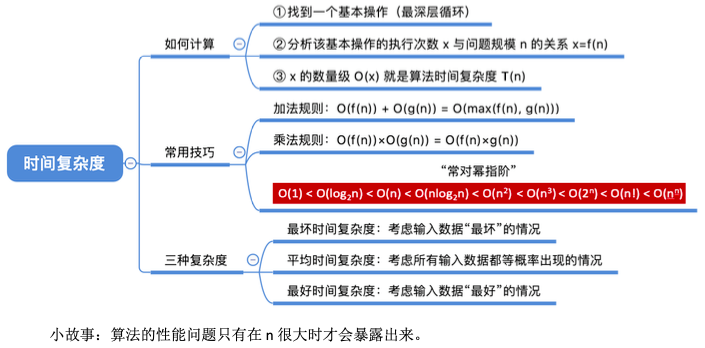
4. 算法效率的度量
时间复杂度:时间开销与问题规模 n 之间的关系
空间复杂度:空间开销(内存开销)与问题规模 n 之间的关系
4.1. 如何评估算法时间开销?
让算法先运行,事后统计运行时间?
存在什么问题?
- 和机器性能有关,如:超级计算机v.s.单片机
- 和编程语言有关,越高级的语言执行效率越低
- 和编译程序产生的机器指令质量有关
- 有些算法是不能事后再统计的,如:导弹控制算法
算法时间复杂度
事前预估算法时间开销T(n)与问题规模 n 的关系(T 表示 “time”)
4.2. 算法的时间复杂度
一个语句的频度f(n)是指该语句在算法中被重复执行的次数。
算法中所有语句之和记为T(n),称为算法问题规模n的函数。
时间复杂度主要分析T(n)的数量级。
算法中基本运算的频度(最深层循环内的语句)与T(n)同数量级,通常采用算法中基本运算的频度f(n)来分析算法的时间复杂度。T(n)=O(f(n))
4.2.1. 一重循环
4.2.1.1. 方法一:模拟求解
- 模拟循环的流程,观察趟数和循环终止变量的关系
- 确定循环停止的条件并求解
1 | int i=n*n; |
| t=0 | t=1 | t=2 | t=3 |
|---|---|---|---|
| i=$n^2$ | i=$\frac{n^2}{2}$ | i=$\frac{n^2}{2^2}$ | i=$\frac{n^2}{2^3}$ |
i=$\frac{n^2}{2^t}$=1时停止循环
$2^t$=$n^2$,两边取对数,t=2log2n,T(n)=O(log2n)
1 | int x=0; |
| t=0 | t=1 | t=2 | t=3 |
|---|---|---|---|
| x=0 | x=1 | x=2 | x=3 |
x=t
终止循环n=(x+1)*(x+1)=$x^2$+2x+1,抓大头$x^2$
n=$t^2$,t=$\sqrt{n}$
1 | int sum(int n){ |
| t=0 | t=1 | t=2 | t=3 |
|---|---|---|---|
| i=0 | i=1 | i=2 | i=3 |
| sum=0 | sum=0+1 | sum=0+1+2 | sum=0+1+2+3 |
sum=0+1+2+…+t=$\frac{t(t+1)}{2}$,抓大头$t^2$
终止循环sum=n=$t^2$,t=$\sqrt{n}$
4.2.1.2. 方法二:执行次数相加
1 | int i=n*n; |
| i | 执行次数 |
|---|---|
| $n^2$ | 1 |
| $\frac{n^2}{2}$ | 1 |
| … | … |
| $\frac{n^2}{2^t}$ | 1 |
执行次数相加=t+1
循环终止条件 $\frac{n^2}{2^t}$=1,t=2log2n
执行次数=t+1=2log2n+1
T(n)=O(log2n)
4.2.2. 二重循环
4.2.2.1. 方法一:数组求和法
- 模拟循环的流程,列出外层的值变化
- 列出内循环的执行次数
- 计算执行次数和
1 | int m=0,i,j; |
| 外层值变化 | i=1 | i=2 | i=3 | i=4 | … | i=n-1 |
|---|---|---|---|---|---|---|
| 内循环执行次数2i | 2*1 | 2*2 | 2*3 | 2*4 | … | 2*(n-1) |
执行次数和 = 2*(1+2+3+…n-1)=n(n-1)
T(n)=O($n^2$)
4.2.2.2. 方法二
- 模拟循环的流程,列出外层的值变化
- 列出内层的值的变化
- 计算执行次数和
1 | int i,j; |
| i=0 | i=1 | … | i=n-1 |
|---|---|---|---|
| j=0 | j=0 | j=0 | j=0 |
| j=1 | j=1 | j=1 | j=1 |
| … | … | … | … |
| j=m-1 | j=m-1 | j=m-1 | j=m-1 |
| 执行m次 | 执行m次 | 执行m次 | 执行m次 |
执行次数和=(n-1)m
T(n)=O(mn)
4.2.3. 多重循环
矩阵求和法
- 模拟循环的流程,列出外层的变化
- 列出内循环的执行次数
- 计算执行次数和
1 | int i,j,k; |
最内层循环次数
| j=0 | j=1 | j=2 | j=3 | … | j=n-1 | |
|---|---|---|---|---|---|---|
| i=0 | 0 | |||||
| i=1 | 0 | 1 | ||||
| i=2 | 0 | 1 | 2 | |||
| i=3 | 0 | 1 | 2 | 3 | ||
| … | … | … | … | … | … | |
| i=n-1 | 0 | 1 | 2 | 3 | … | n-1 |
每行求和 1+2+3+…+i=$\frac{i(i+1)}{2}$,抓大头$\frac{i^2}{2}$
所有行相加 $\frac{1^2}{2}+\frac{2^2}{2}+\frac{3^2}{2}+…+\frac{(n-1)^2}{2}$ = O($n^3$)
平方和公式 $\frac{1^2}{2}+\frac{2^2}{2}+\frac{3^2}{2}+…+\frac{n^2}{2}$ =$\frac{n(n+1)(2n+1))}{6}$
4.2.4. 递归函数
- 模拟递归的流程,列出参数的变化
- 找到边界停止的条件,求出递归深度
- 公式递推
1 | int fact(int n){ |
| 递归参数 | 调用递归函数次数 |
|---|---|
| i=n | 1 |
| i=n-1 | 1 |
| i=n-2 | 1 |
| i=n-3 | 1 |
| … | … |
| i=n-t=1 | 1 |
调用递归函数次数之和=t+1=n+1
T(n)=O(n)
1 | int func(int n){ |
| 递归参数 | 调用递归函数次数 |
|---|---|
| i=n | 1 |
| i=n/2 | 1 |
| i=n/$2^2$ | 1 |
| i=n/$2^3$ | 1 |
| … | … |
| i=n/$2^t$=1 | 1 |
调用递归函数次数之和=t+1=log2n+1
T(n)=O(log2n)
1 | int func(int n){ |
| 递归参数 | 调用递归函数次数 |
|---|---|
| i=n | 1 |
| i=n/2 | 2 |
| i=n/$2^2$ | $2^2$ |
| i=n/$2^3$ | $2^3$ |
| … | … |
| i=n/$2^t$=1 | $2^t$ |
调用递归函数次数之和=$\frac{1-2^{t+1}}{1-2}=2^{t+1}-1$=2n-1
T(n) = O(n)
4.2.5.
4.2.6. 案列
4.2.6.1. 算法1-逐步递增
1 | //逐步递增型爱你 |
时间开销与问题规模 n 的关系:T(n)=3n+3
Q1:是否可以忽略表达式某些部分?
只考虑阶数,用大O记法表示
当问题规模 n 足够大时,大O表示“同阶”,同等数量级。即:当 n->∞时, 二者之比为常数,即 T(n)=O(f(n)) 0 $\leqslant$T(n)$\leqslant$Cf(n)
T1(n)=3n+3 => T1(n) = O(n)
T2(n)=n2+3n+1000 => T2(n) = O(n2)
T3(n)=n3 + n2 +9999999 => T3(n) = O(n3)
若 n=3000,则 可以只考虑阶数高的部分
3n = 9000 V.S. T1(n)= 9003
n2 = 9,000,000 V.S. T2(n)= 9,010,000
n3 = 27,000,000,000. V.S. T3(n)= 27,018,999,999
当 n=3000 时,9999n = 29,997,000 远小于 n3 = 27,018,999,999
当 n=1000000时,9999n = 9,999,000,000 远小于 n2 = 1,000,000,000,000
问题规模足够大时, 常数项系数也可以忽略
加法规则
T(n) = T1(n) + T2(n) = O(f(n)) + O(g(n)) = O(max(f(n), g(n)))
乘法规则
T(n) = T1(n) × T2(n) = O(f(n))× O(g(n)) = O(f(n)×g(n))
Eg:T(n)= n3 + n2log2n= O(n3) + O(n2log2n) = O(n3)
常对幂指阶:
O(1) < O(log2n) < O(n) < O(nlog2n) < O(n2) < O(n3) < O(2n) < O(n!) < O(nn)
问题:两个算法的时间复杂度分别如下,哪个的阶数更高(时间复杂度更高)?
T1(n) = O(n)
T2(n) = O(log2n)
T3(n)= n3 + n2log2n=O(n3) + O(n2log2n)=O(n2n) + O(n2log2n)

Q2:如果有好几千行代码, 按这种方法需要一行一行数?
只需考虑最深层循环的循环次数与 n 的关系
结论1:顺序执行的代码只会影响常数项,可以忽略
结论2:只需挑循环中的一个基本操作分析它的执行次数 与 n 的关系即可
1 | //逐步递增型爱你 |
T(3000) = 1000 + 1 + 3001 + 2*3000 + 1
时间开销与问题规模 n 的关系:T(n) = 3n+1003 = O(n)
4.2.6.2. 算法2-嵌套循环
1 | void loveYou(int n){//n为问题规模 |
时间开销与问题规模 n 的关系: T(n) = O(n) + O(n2) = O(n2)
结论3:如果有多层嵌套循环, 只需关注最深层循环循环了几次
4.2.6.3. 算法3-指数递增
1 | void loveYou(int n){//n为问题规模 |
计算上述算法的时间复杂度 T(n): 设最深层循环的语句频度(总共循环的次数)为 x,则由循环条件可知,循环结束时刚好满足 2x > n,x = log2n + 1,T(n) = O(x) = O(log2n)
4.2.6.4. 算法4-搜索数字
1 | void loveYou(int flag[],int n){ |
计算上述算法的时间复杂度 T(n)
很多算法执行时间与输入的数据有关
最好情况:元素n在第一个位置 —- 最好时间复杂度 T(n)=O(1)
最坏情况:元素n在最后一个位置 —- 最坏时间复杂度 T(n)=O(n)
平均情况:假设元素n在任意一个位置的概率相同为1/n —- 平均时间复杂度 T(n)=O(n)
循环次数 x = $\frac{(1+2+3+…+n)}{n}$= $\frac{n(n+1)}{2}$ ,$\frac{n(n+1)}{2}$$\frac{1}{n}$=$\frac{(n+1)}{2}$,T(n)=O(x)=O(n)
4.2.7. 三种复杂度
最坏时间复杂度:最坏情况下算法的时间复杂度
平均时间复杂度:所有输入示例等概率出现的情况下,算法的期望运行时间
最好时间复杂度:最好情况下算法的时间复杂度
4.2.8. 总结
时间复杂度依赖于问题规模n,也取决于待输入数据性质
同一个算法,实现语言的级别越高,执行效率越低
4.3. 程序运行时的内存需求
算法的空间复杂度S(n)定义为该算法所耗费的存储空间,它是问题规模n的函数。S(n)=O(g(n))
一个程序在执行是除需要存储空间来存放本身所用的指令,常数,变量和输入数据外,还需要一些对数据进行操作的工作单元和存储一些为实现计算所需信息的辅助空间。若输入数据所占空间只取决于问题本身,和算法无关,则只需分析除输入和程序之外的额外空间。
4.3.1. O(1)
1 | //逐步递增型爱你 |
装入内存
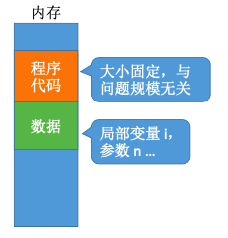
无论问题规模怎么变,算法运行所需的内存空间都是固定的常量,算法空间复杂度为S(n) = O(1) S 表示 “Space”
算法原地工作——算法所需内存空间为常量
4.3.2. O(n)
1 | void test(int n){ |
假设一个 int 变量占 4B,则所需内存空间 = 4 + 4n + 4 = 4n + 8
只需关注存储空间大小与问题规模相关的变量
S(n)=O(n)
4.3.3. O(n*n)
1 | void test(int n){ |
S(n) = O(n2)
1 | void test(int n){ |
S(n) = O(n2)+O(n)+O(1) = O(n2)
T(n) = T1(n) + T2(n) = O(f(n)) + O(g(n)) = O(max(f(n), g(n)))
常对幂指阶:
O(1) < O(log2n) < O(n) < O(nlog2n) < O(n2) < O(n3) < O(2n) < O(n!) < O(nn)
4.3.4. 递归调用
空间复杂度 = 递归调用的深度
1 | void loveYou(int n){ |
递归调用内存
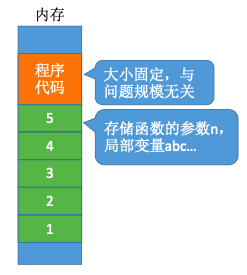

S(n)=O(n)
1 | void loveYou(int n){ |
递归调用
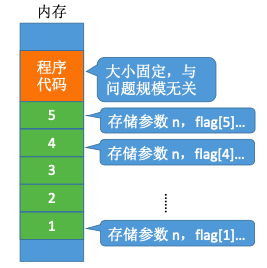
1+2+3+…+n =$\frac{n(n+1)}{2}$ = $\frac{n^2}{2}$ + $\frac{n}{2}$,S(n) = O(n2)
4.3.5. 总结