IO流,NIO http://www.apache.org/
1. File 1.1. 访问文件名相关方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 File file = new File ("/Users/Learning/java/images/a.jpg" );file.getName(); file.getPath(); file.getAbsolutePath(); file.getParent(); file.renameTo(File dest));
1.2. 检测文件相关方法 1 2 3 4 5 6 7 8 9 10 file.exist(); file.canWrite(); file.canRead(); file.isFile(); file.isDirectory(); file.isAbsolute(); file.lastModified(); file.length();
1.3. 操作方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 boolean file.createNewFile(); static File createTempFile (prefix,suffix) ;static File createTempFile (prefix,suffix,directory) ;void deleteOnExit () ;boolean delete () ; boolean mkdir () ; boolean mkdirs () ;String[] list(); File[] listFiles(); static File[] listRoots();
1.4. 打印文件夹下所有文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public static void main (String[] args) throws FileNotFoundException { String path=System.getProperty("user.dir" ); System.out.println(path); File file = new File (path+"/src" ); printFile(file,0 ); } public static void printFile (File file,int level) { for (int i=0 ;i<level;i++){ System.out.print("-" ); } System.out.println(file.getName()); if (file==null ||!file.exists()){ return ; } if (file.isDirectory()){ for (File f: file.listFiles()) { printFile(f,level+1 ); } } }
1.5. 文件过滤器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 file.list(FilenameFilter); public interface FilenameFilter { boolean accept (File dir, String name) ; } String[] files = file.list( (dir,name)->name.endWith("java" )||new File (name).isDirectory()); File[] files =file.listFiles((dir, name) -> name.endsWith(".java" ));
2. Properties 唯一一个集合和IO流相结合的集合
getProperty(String key) - > get(key)
setProperty(String key, String value) - > put(key,value)
key-value默认为字符串
store方法,把集合中的临时数据持久化到硬盘中
load方法,把硬盘中的文件读取到集合中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 public class Properties extends Hashtable <Object,Object>{ public Properties () { this (null ); } public Properties (Properties defaults) { this .defaults = defaults; } public String getProperty (String key) { Object oval = super .get(key); String sval = (oval instanceof String) ? (String)oval : null ; return ((sval == null ) && (defaults != null )) ? defaults.getProperty(key) : sval; } public synchronized Object setProperty (String key, String value) { return put(key, value); } public Set<String> stringPropertyNames () { Hashtable<String, String> h = new Hashtable <>(); enumerateStringProperties(h); return h.keySet(); } public synchronized void load (Reader reader) throws IOException { load0(new LineReader (reader)); } public synchronized void load (InputStream inStream) throws IOException { load0(new LineReader (inStream)); } public void store (Writer writer, String comments) throws IOException { store0((writer instanceof BufferedWriter)?(BufferedWriter)writer: new BufferedWriter (writer),comments,false ); } public void store (OutputStream out, String comments) throws IOException { store0(new BufferedWriter (new OutputStreamWriter (out, "8859_1" )),comments,true ); } }
2.1. 写出到文件 1 2 3 4 5 6 7 8 9 10 String root = System.getProperty("user.dir" )+"/src/main/java/" ; Properties p = new Properties (); p.setProperty("password" ,"123" ); p.setProperty("user" ,"123" ); Writer writer = new FileWriter (root+"account.properties" ); p.store(writer,"account" ); writer.close();
生成文件 account.properties
OutputStream无法存储中文
1 2 3 4 5 6 7 8 9 10 11 String root = System.getProperty("user.dir" )+"/src/main/java/" ; Properties p = new Properties (); p.setProperty("账号" ,"123" ); p.setProperty("密码" ,"123" ); OutputStream out = new FileOutputStream (root+"account.properties" ); p.store(out,"" ); out.close();
中文以unicode形式存储
1 2 \u8D26\u53F7 =123 \u5BC6\u7801 =123
2.2. 读取数据 1 2 3 4 5 6 Reader reader = new FileReader (root+"account.properties" );p.load(reader); Set<String> keys=p.stringPropertyNames(); for (String key:keys) { System.out.println(key+" = " + p.getProperty(key)); }
InputStream无法正确读取中文
1 2 è´¦å· = 123 å¯ç = 123
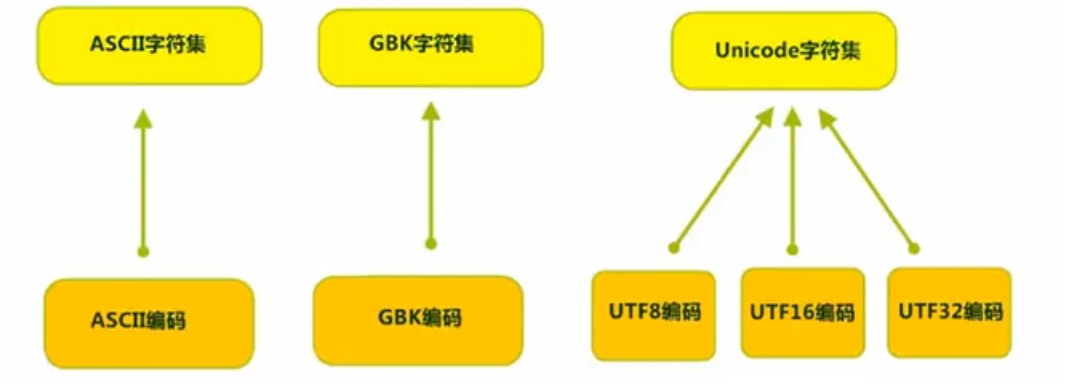
3. 字符集 计算机中储存的信息都是用二进制数表示的,而我们在屏幕上看到的数字、英文、标点符号、汉字等字符是二进制数转换之后的结果。按照某种规则,将字符存储到计算机中,称为编码 。
反之,将存储在计算机中的二进制数按照某种规则解析显示出来,称为解码 。比如说,按照A规则存储,同样按照A规则解析,那么就能显示正确的文本符号。反之,按照A规则存储,再按照B规则解析,就会导致乱码现象。
编码:字符(能看懂的)–>字节(看不懂的)
解码:字节(看不懂的)–>字符(能看懂的)
字符编码 Character Encoding :就是一套自然语言的字符与二进制数之间的对应规则。
编码表:生活中文字和计算机中二进制的对应规则
字符 -> 字节 编码
字节 -> 字符 解码
常用字符集:编码表,系统支持的所有字符的集合,一套字符集至少拥有一套字符编码。
可见,当指定了编码 ,它所对应的字符集 自然就指定了,所以编码 才是我们最终要关心的。
3.1. 虚拟机都必须支持的字符编码
获取编码
1 2 Charset utf8 = StandardCharsets.UTF_8;Charset charset = Charset.forName("UTF-8" );
3.2. ASCII字符集
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)是基于拉丁字母的一套电脑编码系统,用于显示现代英语,主要包括控制字符(回车键、退格、换行键等)和可显示字符(英文大小写字符、阿拉伯数字和西文符号)。
基本的ASCII字符集,使用7位(bits)表示一个字符,共128字符。ASCII的扩展字符集使用8位(bits)表示一个字符,共256字符,方便支持欧洲常用字符。
3.3. ISO-8859-1字符集
拉丁码表,别名Latin-1,用于显示欧洲使用的语言,包括荷兰、丹麦、德语、意大利语、西班牙语等。
ISO-8859-1使用单字节编码,兼容ASCII编码。
3.4. GBxxx字符集
GB就是国标的意思,是为了显示中文而设计的一套字符集。
GB2312 :简体中文码表。一个小于127的字符的意义与原来相同。但两个大于127的字符连在一起时,就表示一个汉字,这样大约可以组合了包含7000多个简体汉字,此外数学符号、罗马希腊的字母、日文的假名们都编进去了,连在ASCII里本来就有的数字、标点、字母都统统重新编了两个字节长的编码,这就是常说的”全角”字符,而原来在127号以下的那些就叫”半角”字符了。GBK :最常用的中文码表。是在GB2312标准基础上的扩展规范,使用了双字节编码方案,共收录了21003个汉字,完全兼容GB2312标准,同时支持繁体汉字以及日韩汉字等。GB18030 :最新的中文码表。收录汉字70244个,采用多字节编码,每个字可以由1个、2个或4个字节组成。支持中国国内少数民族的文字,同时支持繁体汉字以及日韩汉字等。
3.5. Unicode字符集 第一个问题,英文字母只用一个字节表示就够了,第二个问题是如何才能区别Unicode和ASCII?计算机怎么知道两个字节表示一个字符,而不是分别表示两个字符?第三个问题,如果和GBK等双字节编码方式一样,用最高位是1或0表示两个字节和一个字节,就少了很多值无法用于表示字符,不够表示所有字符。Unicode在很长时间内无法推广,直到互联网的出现。UTF(UCS Transfer Format) 面向传输。
Unicode编码系统为表达任意语言的任意字符而设计,是业界的一种标准,也称为统一码、标准万国码。
它最多使用4个字节的数字来表达每个字母、符号,或者文字。有三种编码方案,UTF-8、UTF-16和UTF-32。最为常用的UTF-8编码。
UTF-8编码,可以用来表示Unicode标准中任何字符,它是电子邮件、网页及其他存储或传送文字的应用中,优先采用的编码。每次8个位传输数据 。互联网工程工作小组(IETF)要求所有互联网协议都必须支持UTF-8编码。所以,我们开发Web应用,也要使用UTF-8编码。它使用一至四个字节为每个字符编码,编码规则:
128个US-ASCII字符,只需一个字节编码。
拉丁文等字符,需要二个字节编码。
大部分常用字(含中文),使用三个字节编码。
其他极少使用的Unicode辅助字符,使用四字节编码。
UTF-8 变长unicode字符
UTF-16BE 定长unicode字符,大端表示
UTF-16LE 定长unicode字符,小端表示
UTF-16 文件中指定大端还是小端
ISO-8859-1 拉丁字符
1 2 3 4 5 6 7 8 9 10 11 12 String str="你好" ; byte [] b=str.getBytes();System.out.println(b.length); b = str.getBytes("UTF-16BE" ); System.out.println(b.length); str=new String (b,0 ,b.length,"UTF-8" ); System.out.println(str);
乱码原因
字符长度不够
字符集加解码不统一
4. IO 4.1. 从直观的视角来看 像鼠标键盘属于输入设备,将人的指令转成“鼠键行为”这种数据传给主机;显示器是输出设备,主机通过运算,把“返回信息”这种数据传给显示器。
4.2. 从计算机结构的视角来看 I/O 描述了计算机系统与外部设备之间通信的过程。从硬盘上读取数据到内存,是一次输入,将内存中的数据写入到硬盘就产生了输出。
4.3. 从应用程序的视角来看 IO的主体是其应用程序的运行态,即进程。应用程序的IO操作分为两种动作:IO调用和IO执行。IO调用是由进程发起,IO执行是操作系统的工作。因此,IO是应用程序对操作系统IO功能的一次触发,即IO调用。
IO调用的目的是将进程的内部数据迁移到外部,即输出,将外部数据迁移到进程内部,即输入。这里的外部数据指非进程空间数据,如硬盘,CD-ROM,socket通信传输的网络数据。
一个进程的输入IO调用触发的工作:
进程向操作系统请求外部数据
操作系统将外部数据加载到内核缓冲区
操作系统将数据从内核缓冲区拷贝到进程缓冲区
进程读取数据继续后面的工作
总的来说,应用程序对操作系统的内核发起 IO 调用(系统调用),操作系统负责的内核执行具体的 IO 操作。也就是说,我们的应用程序实际上只是发起了 IO 操作的调用而已,具体 IO 的执行是由操作系统的内核来完成的。
##常见的 IO 模型
UNIX 系统下, IO 模型一共有 5 种: 同步阻塞 I/O 、同步非阻塞 I/O 、I/O 多路复用 、信号驱动 I/O 和异步 I/O 。
4.3.1. 阻塞和非阻塞IO 阻塞和非阻塞强调的是进程对于操作系统IO是否处于就绪状态的处理方式。
应用程序的IO实际是分为两个步骤,IO调用和IO执行。IO调用是由进程发起,IO执行是操作系统的工作。操作系统的IO情况决定了进程IO调用是否能够得到立即响应。如进程发起了读取数据的IO调用,操作系统需要将外部数据拷贝到进程缓冲区,在有数据拷贝到进程缓冲区前,进程缓冲区处于不可读状态,我们称之为操作系统IO未就绪。
进程的IO调用是否能得到立即执行是需要操作系统IO处于就绪状态的,对于读取数据的操作,如果操作系统IO处于未就绪状态,当前进程或线程如果一直等待直到其就绪,该种IO方式为阻塞IO。如果进程或线程并不一直等待其就绪,而是可以做其他事情,这种方式为非阻塞IO。所以对于非阻塞IO,我们编程时需要经常去轮询就绪状态。
4.3.2. 异步和同步IO 同步和异步描述的是针对当前执行线程、或进程而言,发起IO调用后,当前线程或进程是否挂起等待操作系统的IO执行完成。
我们说一个IO执行是同步执行的,意思是程序发起IO调用,当前线程或进程需要等待操作系统完成IO工作并告知进程已经完成,线程或进程才能继续往下执行其他既定指令。
如果说一个IO执行是异步的,意思是该动作是由当前线程或进程请求发起,且当前线程或进程不必等待操作系统IO的执行完毕,可直接继续往下执行其他既定指令。操作系统完成IO后,当前线程或进程会得到操作系统的通知。
以一个读取数据的IO操作而言,在操作系统将外部数据写入进程缓冲区这个期间,进程或线程挂起等待操作系统IO执行完成的话,这种IO执行策略就为同步,如果进程或线程并不挂起而是继续工作,这种IO执行策略便为异步。
4.3.3. 总结 将应用程序的IO操作分为两个步骤来理解:IO调用和IO执行。IO调用才是应用程序干的事情,而IO执行是操作系统的工作。在IO调用时,对待操作系统IO就绪状态的不同方式,决定了其是阻塞或非阻塞模式;在IO执行时,线程或进程是否挂起等待IO执行决定了其是否为同步或异步IO。
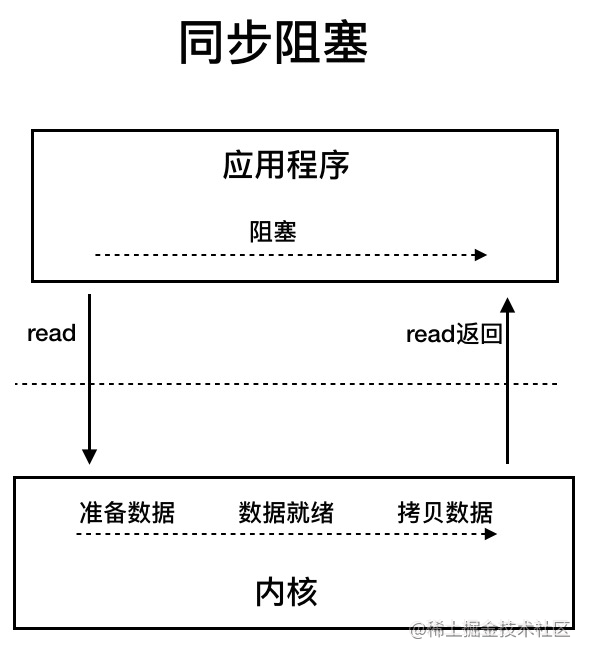
4.3.4. BIO(Blocking I/O) 同步阻塞I/O。应用程序发起 read 调用后,会一直阻塞,直到内核把数据拷贝到用户空间。当面对十万甚至百万级连接的时候,传统的 BIO 模型无法应对如此高的并发量。
4.3.5. NIO (Non-blocking/New I/O) NIO支持面向缓冲,是基于通道的 I/O 操作的,属于I/O 多路复用模型。
IO 多路复用模型中,线程首先发起 select 调用,询问内核数据是否准备就绪,等内核把数据准备好了,用户线程再发起 read 调用。read 调用的过程(数据从内核空间->用户空间)还是阻塞的。
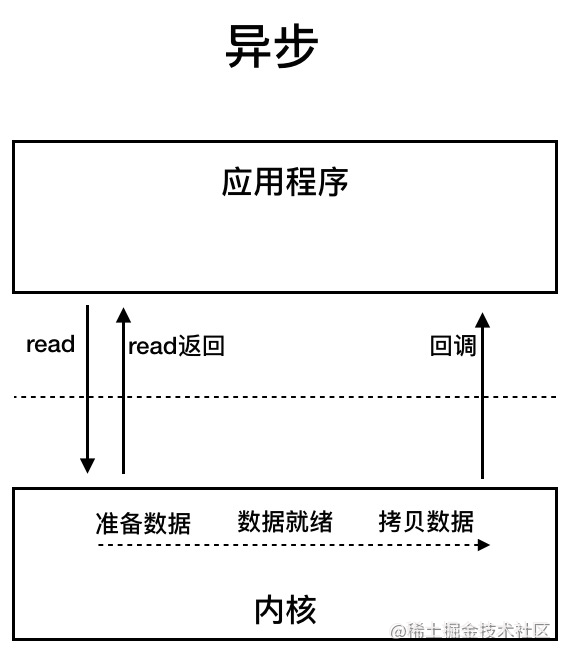
4.3.6. AIO (Asynchronous I/O) 异步 IO 是基于事件和回调机制实现的,也就是应用操作之后会直接返回,不会堵塞在那里,当后台处理完成,操作系统会通知相应的线程进行后续的操作。
5. IO流 输入:硬盘中的数据读取到内存中
输出:内存中的数据写出到硬盘中
输入流:从其中读入一个字节序列的对象
输出流:向其中写入一个字节序列的对象
抽象类InputStream和OutputStream构成了输入输出IO类层次结构的基础
抽象类Reader和Writer专门用于处理Unicode字符
6. 流的分类
6.1. 为什么 I/O 流操作要分为字节流操作和字符流操作呢? 字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。所以, I/O 流就干脆提供了一个直接操作字符的接口,方便对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。
6.2. 输入流 read方法在执行时将阻塞,直至字节确实被读入或写出。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public abstract class InputStream implements Closeable { public abstract int read () throws IOException; public int read (byte b[]) throws IOException{ return read(b, 0 , b.length); } public int read (byte b[], int off, int len) throws IOException {} public int available () throws IOException {} }
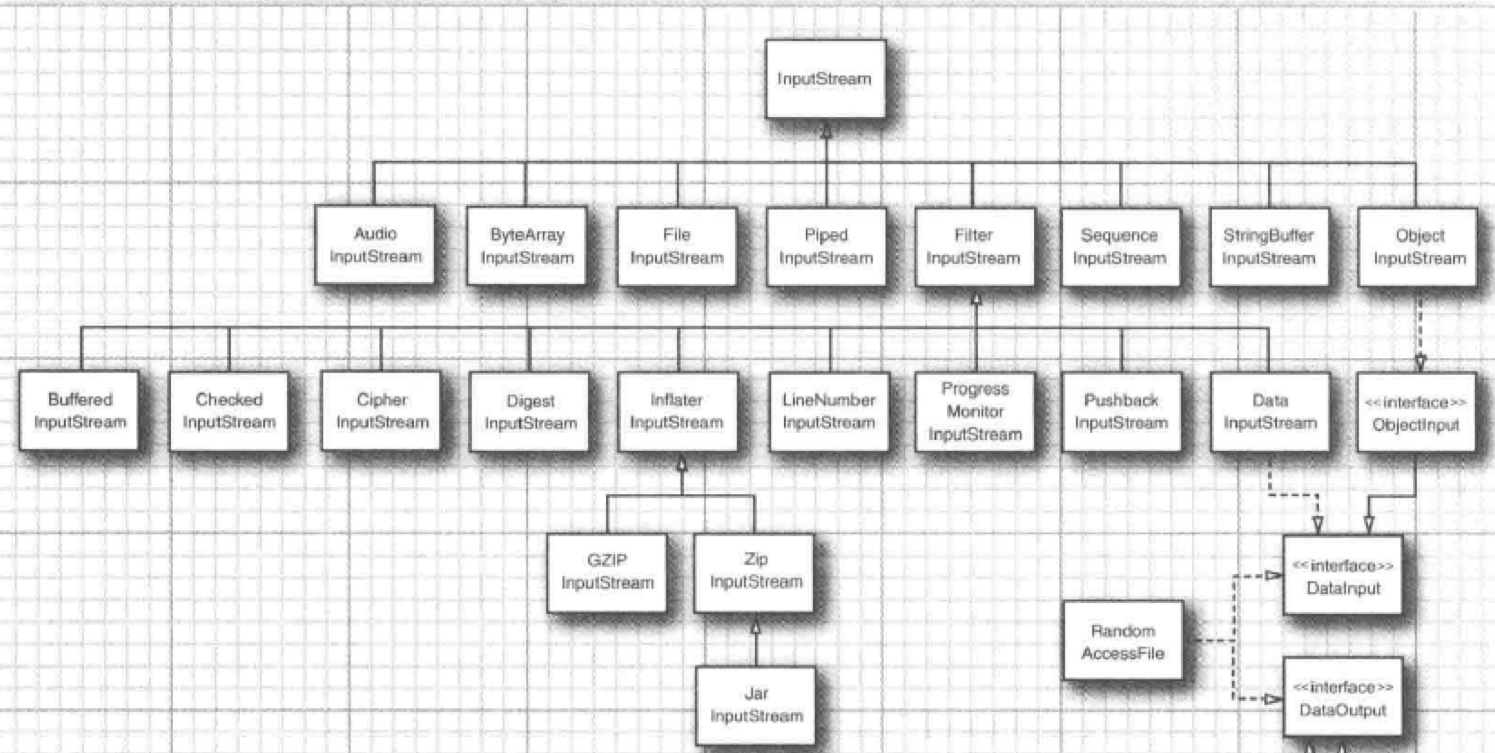
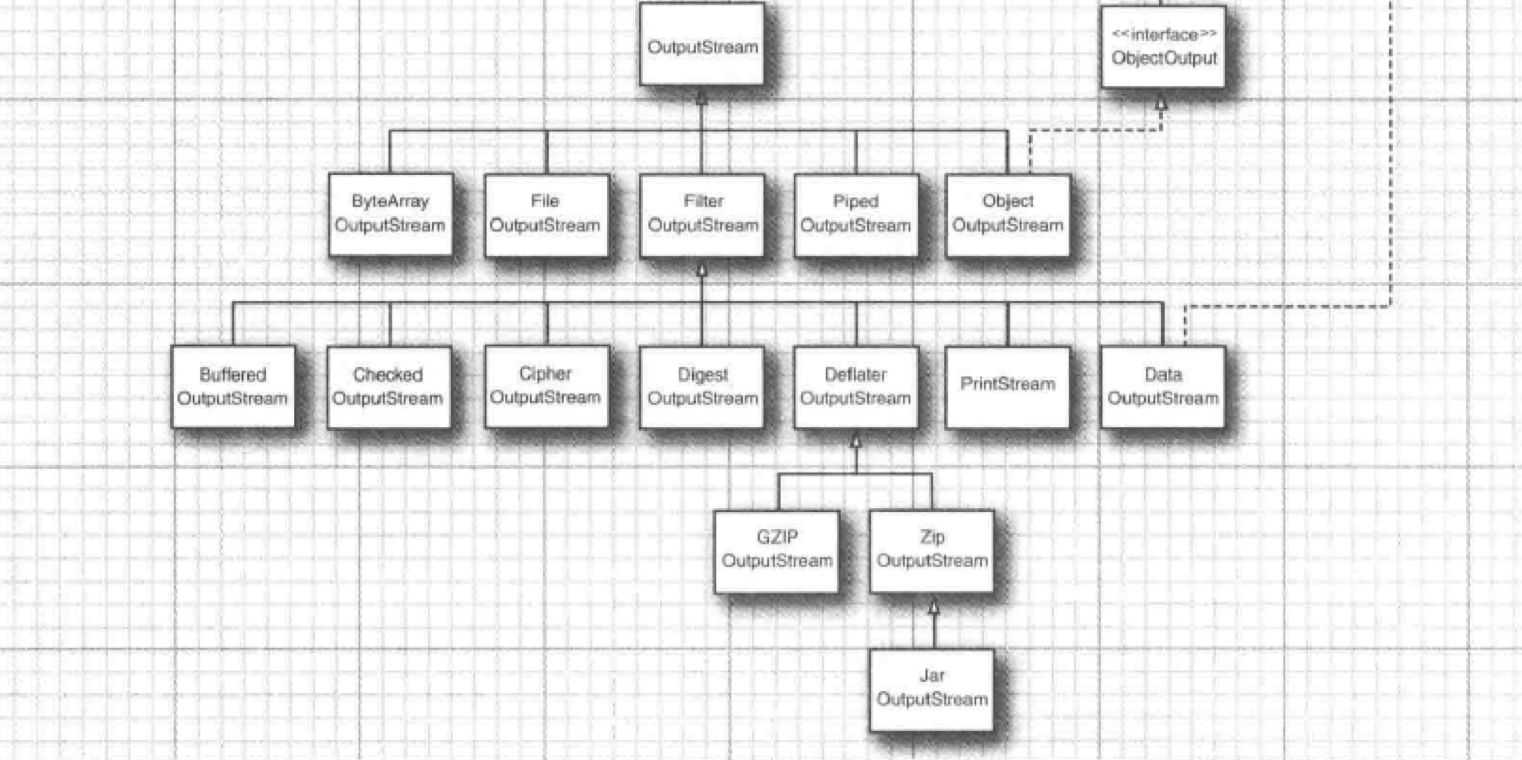
6.2.1.1. 字节输入流层次结构
read是本地方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 class FileInputStream extends InputStream { public FileInputStream (String name) throws FileNotFoundException{ this (name != null ? new File (name) : null ); } public FileInputStream (File file) throws FileNotFoundException{ } public int read () throws IOException { return read0(); } private native int read0 () throws IOException; public int read (byte b[]) throws IOException { return readBytes(b, 0 , b.length); } public int read (byte b[], int off, int len) throws IOException { return readBytes(b, off, len); } private native int readBytes (byte b[], int off, int len) throws IOException; }
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class ByteArrayInputStream extends InputStream { protected byte buf[]; public ByteArrayInputStream (byte buf[]) { this .buf = buf; this .pos = 0 ; this .count = buf.length; } public synchronized int read () { return (pos < count) ? (buf[pos++] & 0xff ) : -1 ; } public synchronized int read (byte b[], int off, int len) {} }
应用
1 2 3 byte [] b = "hello world" .getBytes();ByteArrayInputStream in = new ByteArrayInputStream (b);in.read();
带有缓冲区的流。当缓冲区为空时,向缓冲区读入新数据块
read()
read(byte b[], int off, int len)
read(byte b[])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 public class BufferedInputStream extends FilterInputStream { private static int DEFAULT_BUFFER_SIZE = 8192 ; public BufferedInputStream (InputStream in) { this (in, DEFAULT_BUFFER_SIZE); } public BufferedInputStream (InputStream in, int size) {} public synchronized int read () throws IOException {} public synchronized int read (byte b[], int off, int len) throws IOException{} public int read (byte b[]) throws IOException {} }
读写顺序一致
1 2 3 4 5 6 7 8 9 10 11 12 13 DataInputStream in = new DataInputStream (InputStream);public class DataInputStream extends FilterInputStream implements DataInput { protected volatile InputStream in; public final int read (byte b[]) throws IOException { return in.read(b, 0 , b.length); } }
对象必须序列化: 将数据结构或对象转换成二进制字节流
1 2 3 4 5 6 7 8 ObjectInputStream in = new ObjectInputStream (new FileInputStream (root+"user.txt" ));User u = (User)in.readObject();System.out.println(u); public class ObjectInputStream extends InputStream implements ObjectInput , ObjectStreamConstants{ public final Object readObject () throws IOException, ClassNotFoundException{} }
标记可系列化,仅为标记
transient 表示不被系列化,被 transient 修饰的变量值不会被持久化和恢复。
关于 transient 还有几点注意:
transient 只能修饰变量,不能修饰类和方法。transient 修饰的变量,在反序列化后变量值将会被置成类型的默认值。例如,如果是修饰 int 类型,那么反序列后结果就是 0。static 变量因为不属于任何对象(Object),所以无论有没有 transient 关键字修饰,均不会被序列化。
1 2 3 4 5 6 7 8 9 10 import java.io.Serializable;public class User implements Serializable { private static final long serialVersionUID = 1L ; private String name; private String pwd; } public interface Serializable {}
对于JVM可以反序列化对象,它必须是能够找到class文件的类。如果找不到该类的class文件,则抛出一个 ClassNotFoundException 异常
JVM反序列化对象时,能找到class文件,但是class文件在序列化对象之后发生了修改,那么反序列化操作也会失败,抛出一个InvalidClassException异常。发生这个异常的原因如下:
该类的序列版本号与从流中读取的类描述符的版本号不匹配
该类包含未知数据类型
该类没有可访问的无参数构造方法
Serializable 接口给需要序列化的类,提供了一个序列版本号。serialVersionUID 该版本号的目的在于验证序列化的对象和对应类是否版本匹配
可以预读下一个字节,将不期望的值推回流中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class PushbackInputStream extends FilterInputStream { public PushbackInputStream (InputStream in) { this (in, 1 ); } public PushbackInputStream (InputStream in, int size) {} public void unread (int b) throws IOException { buf[--pos] = (byte )b; } }
用来读zip文档,getNextEntry()将返回文档中的单独项ZipEntry,closeEntry()读入下一项
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 ZipInputStream in = new ZipInputStream (new FileInputStream (str));ZipEntry entry ; while ((entry= in.getNextEntry())!=null ){ int len = -1 ; byte [] buff = new byte [1024 ]; while ((len = in.read(buff))!=-1 ){ System.out.print(new String (buff)); } System.out.println("======" ); in.closeEntry(); }
数据是打印在同一个while里,并没有分ZipEntry
6.2.2. Reader 字符输入流 int read()
int read(char[] b)
int read(char[] b,int off, int len)
1 2 3 4 5 6 Reader in = new FileReader (File);char [] buff = new char [1024 ];int len=0 ;while ((len=in.read(buff))!=0 ){ String str = new String (buff,0 ,len); }
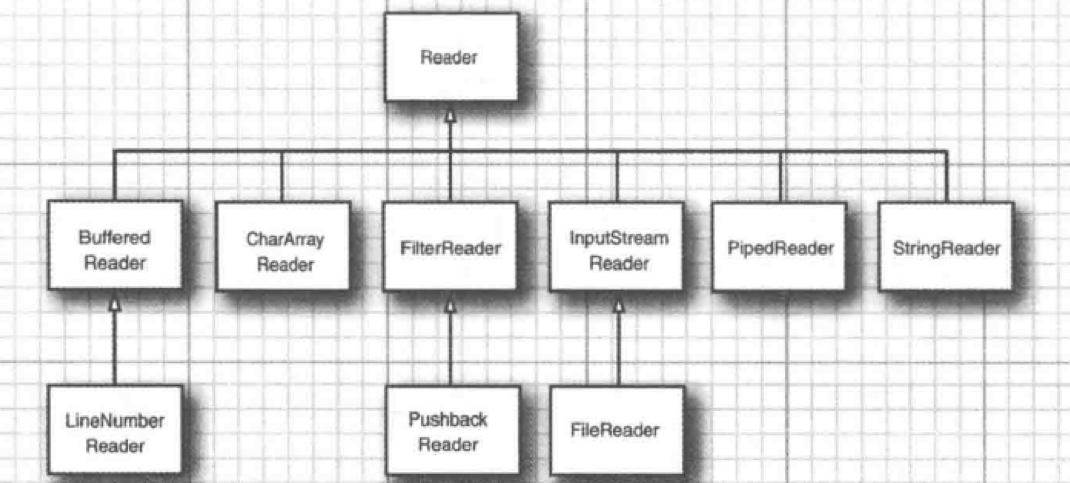
6.2.2.1. Reader层次结构
6.2.2.2. FileReader
//读一个字符
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class FileReader extends InputStreamReader { public FileReader (String fileName) throws FileNotFoundException { super (new FileInputStream (fileName)); } } public class InputStreamReader extends Reader { public InputStreamReader (InputStream in) { super (in); sd = StreamDecoder.forInputStreamReader(in, this , (String)null ); } } public abstract class Reader implements Readable , Closeable { protected Reader (Object lock) { this .lock = lock; } }
6.2.2.3. BufferedReader 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 public class BufferedReader extends Reader { private static int defaultCharBufferSize = 8192 ; private char cb[]; public BufferedReader (Reader in) { this (in, defaultCharBufferSize); } public String readLine () throws IOException { return readLine(false ); } public int read () throws IOException {} public int read (char cbuf[], int off, int len) throws IOException {} public int read (char cbuf[]) throws IOException {} public int read (java.nio.CharBuffer target) throws IOException {} }
应用
1 2 3 4 5 BufferReader r = new BufferedReader (new FileReader (new File ("" )));String str = null ;while ((str=r.readLine())!=null ){ System.out.println(str); }
6.3. 输出流 输出:内存中的数据写出到硬盘中
java程序 -> JVM -> OS操作系统 -> OS调用写数据方法 -> 数据写入文件
写出的字符转换成字节,字节转换成二进制
任意的文件编辑器在打开文件的时候,都会查询编码表,把字节转换为字符表示
文件中显示100 - > 49 48 48 使用3个字节
write(byte[] b)
第一个字节为0-127,那么显示的时候会查询ASCII表
第一个字节为负数,第一个字节和第二个字节组成一个中文显示,默认查询GBK
6.3.1. OutputStream字节输出流 1 2 3 4 5 6 7 8 9 10 11 12 13 public abstract class OutputStream implements Closeable , Flushable { public abstract void write (int b) throws IOException; public void write (byte b[]) throws IOException { write(b, 0 , b.length); } public void write (byte b[], int off, int len) throws IOException {} }
6.3.1.1. 字节输出流层次结构
6.3.1.2. FileOutputStream write方法本质是本地方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public class FileOutputStream extends OutputStream { public FileOutputStream (String name) throws FileNotFoundException { this (name != null ? new File (name) : null , false ); } public FileOutputStream (File file) throws FileNotFoundException { this (file, false ); } public FileOutputStream (String name, boolean append) throws FileNotFoundException { this (name != null ? new File (name) : null , append); } private native void write (int b, boolean append) throws IOException; private native void writeBytes (byte b[], int off, int len, boolean append) throws IOException; }
6.3.1.3. ByteArrayOutputStream 不关联源
1 2 3 4 5 6 7 byte [] b = "hello" .getBytes();ByteArrayOutputStream out = new ByteArrayOutputStream ();out.write(b,0 ,b.length); out.flush(); byte [] dest = out.toByteArray();
6.3.1.4. BufferedOutputStream write(int b)
write(byte b[], int off, int len)
write(byte b[])
1 2 3 4 5 6 7 8 9 10 11 12 13 14 public class BufferedOutputStream extends FilterOutputStream { protected byte buf[]; public BufferedOutputStream (OutputStream out) { this (out, 8192 ); } public BufferedOutputStream (OutputStream out, int size) { buf = new byte [size]; } public synchronized void write (int b) throws IOException {} public synchronized void write (byte b[], int off, int len) throws IOException {} public void write (byte b[]) throws IOException {} }
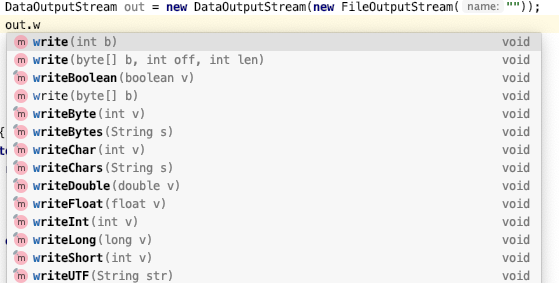
6.3.1.5. DataOutputStream DataOutputStream实现了DataOutput接口,接口中有writeXXX方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 DataOutputStream out = new DataOutputStream ( new FileOutputStream (root+"user.txt" )); out.writeUTF("Hello" ); public class DataOutputStream extends FilterOutputStream implements DataOutput { protected OutputStream out; public DataOutputStream (OutputStream out) { super (out); } public synchronized void write (int b) throws IOException { out.write(b); incCount(1 ); } }
writeInt 总是将一个整数写出为4字节的二进制数量值
writeDouble 总是将一个double值写出为8字节的二进制数量值
writeUTF 首先用UTF-16表示,结果之后用UTF-8进行编码
使得给定类型的每个值所需空间相同,使其读回比解析文本快
Java中所有值都按照高位在前的模式写出
6.3.1.6. ObjectOutputStream 对象流,拥有方法writeObject,用于对象序列化
1 2 3 4 5 6 7 8 9 10 11 ObjectOutputStream out = new ObjectOutputStream ( new FileOutputStream (root+"user.txt" )); out.writeObject(new User ("a" ,"123" )); out.flush(); out.close(); public class ObjectOutputStream extends OutputStream implements ObjectOutput , ObjectStreamConstants { public final void writeObject (Object obj) throws IOException {} }
6.3.1.7. ZipOutputStream ZipEntry可以设置文件日期,解压缩方法setCrc(long)等参数,putNextEntry(ZipEntry)来写出文件
1 2 3 4 ZipOutputStream out = new ZipOutputStream (new FileOutputStream ("压缩文件名" ));ZipEntry entry = new ZipEntry ("文件名" );out.putNextEntry(entry); out.closeEntry();
6.3.2. Writer 字符输出流 public void write(int c) 单个字符
public void write(char cbuf[]) 字符数组输出到输出流中
abstract public void write(char cbuf[], int off, int len) 从off位置开始,长度为len的字符输出到输出流
public void write(String str)
public void write(String str, int off, int len)
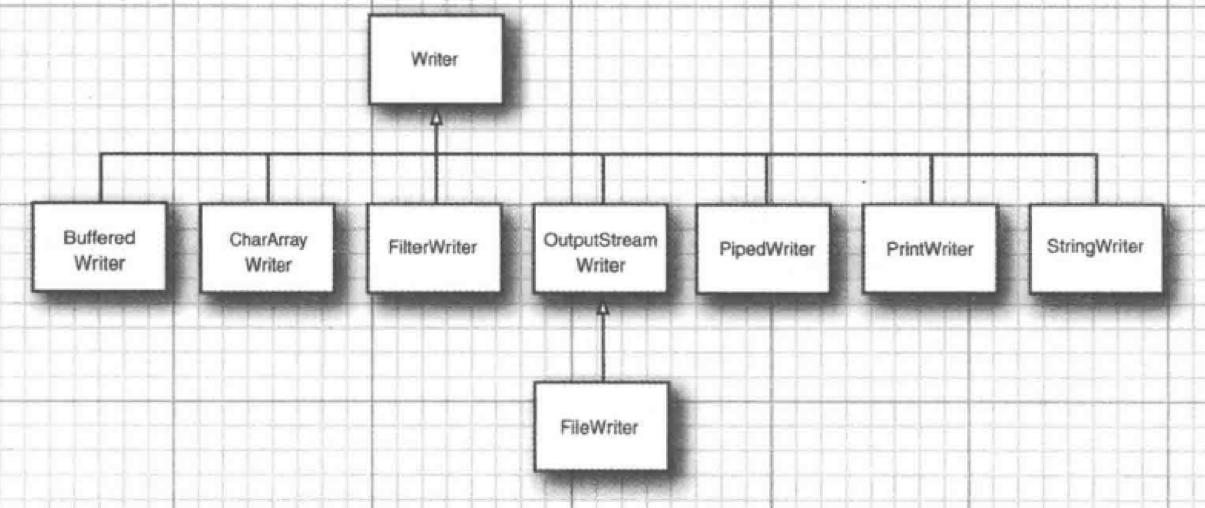
6.3.2.1. Writer层次结构
父子类
Writer - > OutputStreamWriter - > FileWriter
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 Writer out = new FileWriter (File);out.write(1 ); out.flush(); out.close(); public class FileWriter extends OutputStreamWriter { private char [] writeBuffer; private static final int WRITE_BUFFER_SIZE = 1024 ; public FileWriter (String fileName) throws IOException { super (new FileOutputStream (fileName)); } } public class OutputStreamWriter extends Writer { public OutputStreamWriter (OutputStream out, String charsetName) throws UnsupportedEncodingException{} public OutputStreamWriter (OutputStream out) { super (out); try { se = StreamEncoder.forOutputStreamWriter(out, this , (String)null ); } catch (UnsupportedEncodingException e) { throw new Error (e); } } } public abstract class Writer implements Appendable , Closeable, Flushable { protected Writer (Object lock) { if (lock == null ) { throw new NullPointerException (); } this .lock = lock; } }
read,write方法执行都将阻塞,直至字节确实被读入或写出。
6.3.2.2. flush() 把内存缓冲区的数据刷新到文件中
关闭输出流的同时冲刷缓冲区,所有被放置于缓冲区,以便用更大的包的形式传递的字符在关闭输出流时都将被送出。如果不关闭文件,写出字节的最后一个包可能永远得不到传递。
6.3.2.3. close() 释放资源,把仍在缓冲区中的数据刷新到文件中
6.3.2.4. BufferedWriter 1 2 3 4 BufferedWriter w = new BufferedWriter (new FileWriter (new File ("" )));w.write(str); w.newLine();
代码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 public class BufferedWriter extends Writer { private static int defaultCharBufferSize = 8192 ; public BufferedWriter (Writer out) { this (out, defaultCharBufferSize); } public void write (int c) throws IOException { synchronized (lock) { ensureOpen(); if (nextChar >= nChars) flushBuffer(); cb[nextChar++] = (char ) c; } } public void newLine () throws IOException { write(lineSeparator); } abstract public void write (char cbuf[], int off, int len) throws IOException; public void write (String str, int off, int len) throws IOException { synchronized (lock) { } } public void write (char cbuf[]) throws IOException { write(cbuf, 0 , cbuf.length); } public void write (String str) throws IOException { write(str, 0 , str.length()); } }
6.4. 转换流 编码 字符->字节
1 2 BufferedReader br = new BufferedReader (new InputStreamReader (new FileInputStream (new File (name)),"UTF-8" ));String str = br.readLine();
6.4.2. OutputStreamWriter 解码 字节->字符
1 2 BufferedWriter bw = new BufferedWriter (new OutputStreamWriter (new OutputStreamWriter (new File (name)),"UTF-8" ));bw.newLine();
6.5. 重定向 6.5.1. PrintStream PrintStream不会抛出IOException异常
调用特有方法print,println,97->97
调用父类的write方法写数据,查看数据会查询编码表,97->a
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 public class PrintStream extends FilterOutputStream implements Appendable , Closeable{ public PrintStream (String fileName) throws FileNotFoundException {} public PrintStream (File file) throws FileNotFoundException { this (false , new FileOutputStream (file)); } public PrintStream (OutputStream out) { this (out, false ); } public PrintStream (OutputStream out, boolean autoFlush) { this (autoFlush, requireNonNull(out, "Null output stream" )); } private PrintStream (boolean autoFlush, OutputStream out) {} public void print (char c) { write(String.valueOf(c));} public void print (boolean b) { write(b ? "true" : "false" );} public void print (int i) { write(String.valueOf(i));} public void print (long l) { write(String.valueOf(l));} public void print (float f) {write(String.valueOf(f));} public void print (double d) {write(String.valueOf(d));} public void print (char s[]) {write(s);} public void print (Object obj) { write(String.valueOf(obj));} public void print (String s) { if (s == null ) { s = "null" ; } write(s); } public void println (int x) { synchronized (this ) { print(x); newLine(); } } private void write (String s) { try { synchronized (this ) { ensureOpen(); textOut.write(s); textOut.flushBuffer(); charOut.flushBuffer(); if (autoFlush && (s.indexOf('\n' ) >= 0 )) out.flush(); } } catch (InterruptedIOException x) { Thread.currentThread().interrupt(); } catch (IOException x) { trouble = true ; } } }
System.in –> InputStream 从键盘输入
1 public final static InputStream in = null ;
System.err –> PrintStream(OutputStream)
1 public final static PrintStream err = null ;
System.out –> PrintStream(OutputStream) 从键盘输出
1 public final static PrintStream out = null ;
6.5.2. 重定向-输出到文件 1 2 3 4 5 6 7 8 public final class System { public static void setOut (PrintStream out) {} public static void setErr (PrintStream p) {} public static void setIn (InputStream p) {} } System.setOut(new PrintStream ("a.txt" )); System.out.println("hahaha" );
6.5.3. 回控制台 1 2 3 4 5 6 7 System.out( new PrintStream ( new BufferedOutputStream ( new FileOutputStream (FileDescriptor.out) ),true ) );
6.6. 任意访问RandomAccessFile 可以在文件中的任何位置查找或写入数据,RandomAccessFile类同时实现了DataInput和DataOutput接口,可以调用readXXX和writeXXX方法进行读写
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 RandomAccessFile file = new RandomAccessFile (File,访问模式);public class RandomAccessFile implements DataOutput , DataInput, Closeable { public native long getFilePointer () throws IOException; public void seek (long pos) throws IOException { if (pos < 0 ) { throw new IOException ("Negative seek offset" ); } else { seek0(pos); } } private native void seek0 (long pos) throws IOException; }
访问模式可以为:
r :读
rw :读写
rws :读写并同步到底层存储设备
rwd :每个更新同步到底层存储设备
可以进行读写操作
1 2 3 4 file.read(); file.write(); file.writeUTF();
6.7. 序列化 Serializable接口仅为可序列化的标识
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public class A implements Serializable { } String name = "a.txt" ;ObjectOutputStream obj = new ObjectOutputStream ( new FileOutputStream (name)); obj.writeObject(new A ()); obj.flush(); obj.close(); ObjectInputStream obj = new ObjectInputStream ( new FileIntoutStream (name)); A a = (A)obj.readObject();obj.close();
对象系列化中对象都关联一个序列号,如ArrayList
1 private static final long serialVersionUID = 8683452581122892189L ;
6.7.1. 对象系列化过程 对于ObjectOutputStream
对于每个对象,当第一次遇到时,保存其对象数据到输出流中
某个对象之前已经被保存过,那么只写出“与之前保存过的序列号相同的对象”
对于ObjectInputStream
在第一次遇到其序列号时,构建它,并使用流中数据来初始化它,记录序列号
当遇到相同序列号时,直接获取对象引用
序列化检查对象对象的序列号,只有对象从未被序列化过,系统才会将该对象序列化,序列号存在的情况下,仅返回序列号
transient代表该变量不被序列化,序列时忽略该实例变量
6.7.2. 序列号 对象所属类描述包括:
类名
系列化的版本唯一ID,它是数据域类型和方法签名的指纹
描述系列化方法的标志集
对数据域的描述
指纹是通过对类,超类,接口,域类型和方法签名按照规范方式排序,然后将安全散列算法(SHA)应用于这些数据而获得的。
SHA算法无论数据块尺寸大小,返回结果总是20个字节的数据。序列化机制只使用SHA码的前8个字节作为类的指纹。
读入对象数据时,如果存在不同版本 :
只有方法产生了变化,那么读入新对象数据时不会有任何问题。
如果数据域发生了改变:
如果数据域之间名字匹配而类型不匹配,输入流不会尝试将一种类型转换成另一种类型。
如果数据域具有之前版本所没有的数据域,那么对象输入流将忽略这些额外数据
如果数据域比之前版本的数据域少,少的数据域将被添加并被设置成默认值(null,0,false)
7. CommonsIO http://commons.apache.org/proper/commons-io/download_io.cgi
8. java.nio.file 该包中定义的类方法可以更快速操作文件
8.1. Path Path表示一个目录名系列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 public final class Paths { public static Path get (String first, String... more) { return FileSystems.getDefault().getPath(first, more); } } public interface Path extends Comparable <Path>, Iterable<Path>, Watchable { Path resolve (String other) ; Path resolveSibling (Path other) ; File toFile () ; }
案例
1 2 3 4 5 6 7 Path path = Paths.get("src" ,"main" );Path resolve = path.resolve("a.txt" );path = Paths,get("src" ,"main" ,"a.txt" ); Path sibling = path.resolveSibling("b.txt" );
8.2. Files Files类封装了在机器上处理文件系统所需要的所有功能,IO流注重文件内容,而Files注重文件在磁盘上的存储。Files使得文件操作更为快捷。
8.2.1. 读取文件内容 8.2.1.1. readAllLines(Path,Charset) 可以直接一行行读取文件内容
1 2 3 4 5 File file = new File ("a.txt" );List<String> list = Files.readAllLines(file.toPath(), StandardCharsets.UTF_8); list.stream().forEach(System.out::println);
8.2.1.2. lines(Path) 文件内容读入到流中
1 2 3 4 5 File file = new File ("a.txt" );Stream<String> stream = Files.lines(file.toPath()); stream.forEach(System.out::println);
8.2.1.3. walk(Path) 可以处理目录下所有文件,包括子目录
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 public static Stream<Path> walk (Path start, FileVisitOption... options) throws IOException { return walk(start, Integer.MAX_VALUE, options); } public static Stream<Path> walk (Path start, int maxDepth, FileVisitOption... options) {}public enum FileVisitOption { FOLLOW_LINKS; }
8.2.1.4. walkFileTree(Path,FileVisitor) 访问目录下所有子孙成员
1 public static Path walkFileTree (Path start, FileVisitor<? super Path> visitor) {}
8.2.1.4.1. FileVisitor 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 public interface FileVisitor <T> { FileVisitResult preVisitDirectory (T dir, BasicFileAttributes attrs) throws IOException; FileVisitResult visitFile (T file, BasicFileAttributes attrs) throws IOException; FileVisitResult visitFileFailed (T file, IOException exc) throws IOException; FileVisitResult postVisitDirectory (T dir, IOException exc) throws IOException; }
8.2.1.4.2. FileVisitResult 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 public enum FileVisitResult { CONTINUE, TERMINATE, SKIP_SUBTREE, SKIP_SIBLINGS; }
8.2.1.4.3. 案例一查看txt文件内容 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 @Test void testSystem () throws IOException { String str = System.getProperty("user.dir" )+"/src/a.txt" ; Path path = Files.walkFileTree(Paths.get(str), new SimpleFileVisitor <Path>() { @Override public FileVisitResult preVisitDirectory ( Path dir, BasicFileAttributes attrs) throws IOException { System.out.println("start" ); return FileVisitResult.CONTINUE; } @Override public FileVisitResult visitFile ( Path path, BasicFileAttributes attrs) throws IOException { Stream<String> stream = Files.lines(path); System.out.println("ing....." ); stream.forEach(System.out::println); return FileVisitResult.CONTINUE; } @Override public FileVisitResult postVisitDirectory ( Path dir, IOException exc) throws IOException { System.out.println("end" ); return FileVisitResult.TERMINATE; } @Override public FileVisitResult visitFileFailed ( Path file, IOException exc) throws IOException { System.out.println("error" ); return FileVisitResult.SKIP_SUBTREE; } }); }
8.2.1.4.4. 案例二查看zip文档内容 public static FileSystem newFileSystem(Path path,ClassLoader loader)
对所安装的文件系统提供者进行迭代。如果loader不为null,那么就迭代给定的类加载器能够加载的文件系统,返回由第一个可以接受给定路径的文件系统提供者创建的文件系统。
public abstract Path getPath(String first, String... more);
将给定的字符串连接起来创建一个路径
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 @Test void testSystem () throws IOException { String str = System.getProperty("user.dir" )+"/src/404.zip" ; FileSystem system = FileSystems.newFileSystem(Paths.get(str), null ); Path path = Files.walkFileTree( system.getPath("/" ), new SimpleFileVisitor <Path>() { @Override public FileVisitResult preVisitDirectory ( Path dir, BasicFileAttributes attrs) throws IOException { System.out.println("start" ); return FileVisitResult.CONTINUE; } @Override public FileVisitResult visitFile ( Path path, BasicFileAttributes attrs) throws IOException { Stream<String> lines = Files.lines(path); System.out.println("ing....." ); lines.forEach(System.out::println); return FileVisitResult.CONTINUE; } @Override public FileVisitResult postVisitDirectory ( Path dir, IOException exc) throws IOException { System.out.println("end" ); return FileVisitResult.TERMINATE; } @Override public FileVisitResult visitFileFailed ( Path file, IOException exc) throws IOException { System.out.println("error" ); return FileVisitResult.SKIP_SUBTREE; } }); }
8.2.1.5. newDirectoryStream(Path,glob模式) 专门用于目录遍历的接口,glob模式可以过滤文件
1 public static DirectoryStream<Path> newDirectoryStream (Path dir, String glob) {}
glob模式:
模式
描述
示例
*
匹配路径组成部分中0或多个字符
*.java匹配当前目录中的所有java文件
**
匹配跨目录边界的0或多个字符
**.java匹配当前目录下所有子目录的java文件
?
匹配一个字符
????.java匹配所有四个字符的java文件
[…]
匹配一个字符集合,可以使用连线符[0-9]和取反符[!0-9]
Test[0-9A-F].java匹配Testx.java,x是十六进制数字
{…}
匹配由逗号隔开的多个选项之一
*.{java,class}匹配所有的java文件和类class文件
\
转义上述任意模式中的字符以及\字符
*\**匹配所有文件中包含*的文件
8.2.2. 写出到文件 8.2.2.1. write(Path, byte[], OpenOption) 写入byte[]内容到文件Path
1 2 3 4 5 6 7 8 9 10 11 12 13 public static Path write (Path path, byte [] bytes, OpenOption... options) {}Path path = Files.write( Paths.get("a.txt" ), "Hello" .getBytes(), StandardOpenOption.APPEND);
8.2.3. 获取文件信息 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 public static long size (Path path) throws IOException {}public static boolean exists (Path path, LinkOption... options) {}public enum LinkOption implements OpenOption , CopyOption { NOFOLLOW_LINKS; } public static boolean isReadable (Path path) {}public static boolean isWritable (Path path) {}
8.2.4. 操作文件 8.2.4.1. createDirectory(Path) 创建新目录
1 2 3 4 5 public static Path createDirectory (Path dir, FileAttribute<?>... attrs) {}public static Path createDirectories (Path dir, FileAttribute<?>... attrs) {}
8.2.4.2. copy(Path,Path,CopyOption) 复制文件
1 public static Path copy (Path source, Path target, CopyOption... options)
8.2.4.3. move(Path,Path,CopyOption) 复制并删除原文件
1 public static Path move (Path source, Path target, CopyOption... options)
8.2.4.4. delete(Path) 删除文件
1 public static void delete (Path path) throws IOException {}
8.2.4.5. deleteIfExists(Path) 删除存在的文件
1 public static boolean deleteIfExists (Path path) throws IOException {}
8.2.5. 文件操作选项 8.2.5.1. StandardOpenOption 在写入中使用的文件操作选项
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 public enum StandardOpenOption implements OpenOption { READ, WRITE, APPEND, TRUNCATE_EXISTING, CREATE, CREATE_NEW, DELETE_ON_CLOSE, SPARSE, SYNC, DSYNC; }
8.2.5.2. StandardCopyOption 文件拷贝,移动时操作选项
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 public enum StandardCopyOption implements CopyOption { REPLACE_EXISTING, COPY_ATTRIBUTES, ATOMIC_MOVE; }
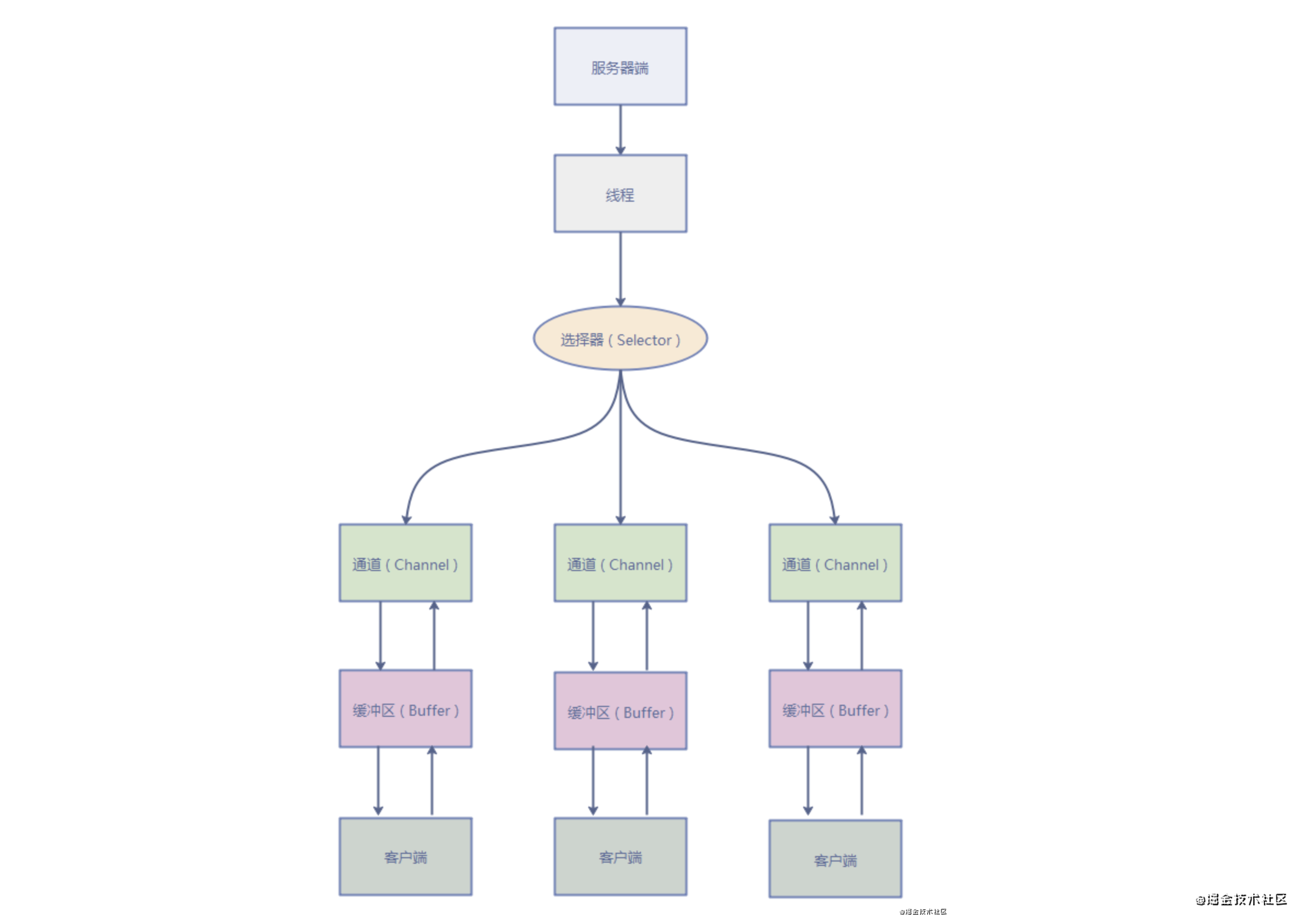
9. NIO 传统的输入流在没有读取到数据时,会发生阻塞,IO流都是阻塞式输入输出,他们都依赖于字节的移动来处理数据。
新的IO采用内存映射文件的方式处理输入输出,将文件的一段区域映射到内存中。
Channel 通道,对应于传统IO,提供的map()将一块数据映射到内存中
Buffer 缓冲数组,发送到Channel的数据先放入Buffer中,从Channel中读取的数据也先放入Buffer中。
9.1. Channel 通道是用于磁盘文件的一种抽象,可以访问内存映射,文件加锁机制以及文件间快速数据传递等操作系统特性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 FileChannel in = new FileInputStream (new File ("a.txt" )).getChannel();FileChannel out = new FileOutputStream (new File ("a.txt" )).getChannel();FileChannel channel = FileChannel.open( Paths.get("a.txt" ), StandardOpenOption.APPEND); MappedByteBuffer buffer = in.map( FileChannel.MapMode.READ_ONLY,0 ,new File ("a.txt" ).length()); Charset ch = Charset.forName("UTF-8" );out.write(buffer); buffer.clear(); CharsetDecoder decoder= ch.newDecoder(); CharsetBuffer cb = decoder.decode(buffer);cb.toString();
MapMode,操作缓冲区方式
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 public static class MapMode { public static final MapMode READ_ONLY = new MapMode ("READ_ONLY" ); public static final MapMode READ_WRITE = new MapMode ("READ_WRITE" ); public static final MapMode PRIVATE = new MapMode ("PRIVATE" ); }
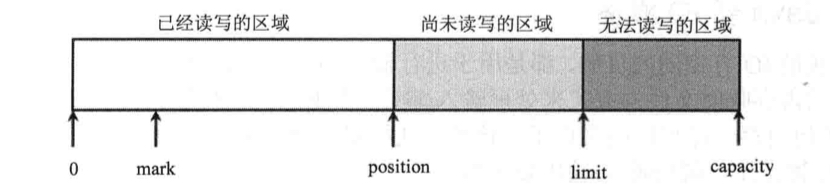
9.2. Bufffer
标记mark:用于重复一个读入或写出的操作
位置position:指向下一个可操作的索引
界限limit:第一个不应该被操作的索引
容量capacity:最大数据容量
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 ByteBuffer buffer = ByteBuffer.allocate(1024 );Buffer clear = buffer.clear();Buffer flip = buffer.flip();int capacity = buffer.capacity();Buffer mark = buffer.mark();int remain = buffer.remaining();byte get () ;byte get (int index) ;int getInt () ;int getInt (int index) ;long getLong () ;long getLong (int index) ;float getFloat () ;float getFloat (int index) ;double getDouble () ;double getDouble (int index) ;ByteBuffer put (byte b) ; ByteBuffer putInt (int value) ; ByteBuffer putShort (short value) ; ByteBuffer putChar (char value) ; ByteBuffer putLong (long value) ; ByteBuffer putFloat (float value) ; ByteBuffer putDouble (double value) ;
9.3. 文件锁 多个同时执行的程序修改同一个文件情形。
FileLock 并发锁定文件
1 2 3 4 5 6 FileLock lock = channel.lock();FileLock lock1 = channel.tryLock();lock.release();
lock() 在没有得到文件锁时,一直阻塞
1 lock(long position, long size, boolean shared)
从position位置开始,长度为size的文件段阻塞式加锁
tryLock() 尝试获取文件锁,没有则返回null,有则返回文件锁
1 trylock(long position, long size, boolean shared)
shared为true则为共享锁,允许多进程读取文件。为false,锁定文件的读写。