C语言集训营——关键字,常量,变量,数据类型,输入输出,运算符与表达式,选择结构程序设计,函数,结构体
1. C语言
C语言为什么叫C语言呢?其实是因为先有高级语言ALGOL60(A语言),后来它经过简化变为BCPL语言(B语言),而C语言是在B语言的基础之上发展而来的,所以称之为C语言。在世界上第一个C语言编译器是用B语言编写的。目前,主流的编译器是微软公司的Visual Studio使用的masm编辑器和Linux使用的gcc编译器。学习一堆关于C的版本和标准意义不大,关键是要掌握编辑器支持的语言特性
1.1. UNIX
1965年前,计算机并不像今天这样普遍,它不是普通人能用得起的,除非是军事机构或学院研究机构。当时,大型主机最多能支持30个终端(30个键盘,显示器),为了解决终端数量不足的问题,1965年前后,贝尔实验室加入麻省理工学院和通用电气公司的合作计划,以便建立一套多用户,多处理器,多层次的MULTICS操作系统,让大型主机支持300个终端。
1965年前后,该项目进展缓慢,资金短缺,贝尔实验室退出实验室。1969年8月,从这个项目中退出的Ken Thompson 为了能在实验室中一台空闲的计算机上运行“星际旅行(Space Travel)“游戏,在妻子探亲的1个月时间内,使用汇编语言编写了UNIX操作系统的原型。
1970年,Ken Thompson 以BCPL语言为基础,设计出了很简单且接近硬件的B语言,并且B语言编写了第一个UNIX操作系统。
1971年,同样酷爱“星级旅行”的Dennis M.Ritchie 为了能早一些玩上这款游戏,加入了Ken Thompson的开发项目,合作开发了UNIX操作系统。他的主要工作是改造B语言,因为B语言跨平台性较差。
1972年,Dennis M.Ritchie 在B语言的基础上最终设计出了一种新语言,他以BCPL的第二个字母作为这种语言的名字,这就是C语言。
1973年初,C语言的主体完成,Ken Thompson 和 Dennis M.Ritchie 迫不及待地开始用它完全重写了现在大名鼎鼎的UNIX操作系统。
1.2. C
在把UNIX操作系统移植到其他类型的计算机上使用时,C语言强大的移植性得以显现。机器语言和汇编语言都不具有移植性,为x86开发的程序,不可能在Alpha,SPARC和ARM等机器上运行。而C程序则可以在任意架构的处理器上使用,只要这种架构的处理器具有对应的C语言编译器和库,将C源代码编译,链接成目标二进制文件即可运行。
跨平台 无须修改即可在任何平台上运行。如:java,python
可移植 可以通过不同的编译器编译后在任何平台上运行。
C语言是可移植不可跨平台的语言。因为C语言除文件操作外,还未涉及到操作系统硬件资源的接口,如进程调度,网络通信等,这些接口均是每个操作系统独有的,因为Windows和Linux的这些接口有所差异。一旦C程序中使用了这些接口,将代码放到另一个平台上就无法编译通过。
那么C语言就不如Java语言?
不然,Windows操作系统本身使用C/C++和少量的汇编语言开发的,Linux是用C和少量汇编语言开发的,C语言执行效率在高级语言中一直位居第一。另外,Java语言及其他脚本语言中没有指针,无法访问物理地址,所以系统中的驱动都要用C或C++语言进行编写。
1.3. 编译过程
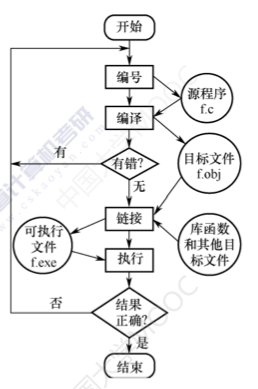
- 首先
编写源程序f.c - 编写完毕后,通过编译器进行
编译,这里的编译包括预处理,编译,汇编。详情请阅读编译原理的书籍。f.c经过编译后,得到f.obj文件- f.obj文件由均是0/1类型的机器码,即CPU能够识别的微指令。f.obj文件并不能执行,因为调用的标准库函数的代码并不在f.obj文件中。如输出函数printf,并不会在f.obj中
- 经过
链接才能得到可执行文件f.exe - 了解这个编译过程,后面在编写程序遇到编译错误时,就可以分析错误,进而区分是编译错误还是链接错误
1.4. 学习C语言后的境界
达到的效果是理解程序的执行过程,对于理解程序的执行过程,C语言是当之无愧的最佳选择,因为其他高级语言封装的内容太多,程序执行的过程是什么?其实,程序执行的过程简单来说就是内存的变化过程。打个比方:内存的变化过程就像衣柜的变化过程,通过内存来存储数据,就像通过衣柜来存储衣服。数据存储要有规律,以便高效取出;衣服存放要有次序,否则可能会花很长时间找想要的那件衣服,当然,程序员的级别更高级,更像裁缝,衣柜里所放的原始布料相当于做好的衣服有规律地放在衣柜中,以便需要时提供给客户;程序员也需要把处理好的数据放好,以便在用户需要时显示给用户。
另外要掌握的能力是程序的调试能力,要灵活掌握单步调试,判断打印等手段,要能在清晰理解程序执行过程的基础上准确分析数据的变化过程,定位程序的问题点,进而解决问题。学好了C语言,以后在学习其他任何语言并调试程序的问题时就会事半功倍。
2. 编译软件VSCode
2.1. 下载软件
https://code.visualstudio.com/Download
2.2. 安装插件
C/C++
中文语言包
2.3. 新建文档
打开VSCode首页添加工作区间,新建文档 test.c

2.4. 启动编译
选择左侧的【运行和调试】,选择环境【C++(GDB/LLDB)】,【gcc】
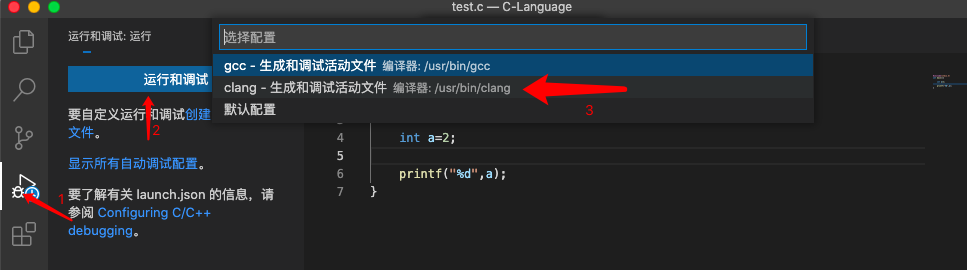
运行终端出现【终端将被任务重用,按任意键关闭】

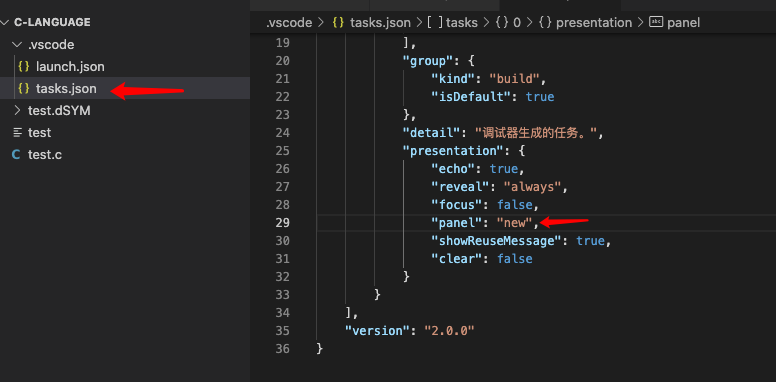
在文件夹中出现了【tasks.json】,在文档中加上presentation,其中的panel属性可以用shared和new,shared表示终端共享使用,new的话就是再建一个终端来显示
此时可以正常显示
并可以正常输出
2.5. 支持scanf函数
搜索【codelldb】,进行安装
修改launch.json,文件位于文件夹的【.vscode】中
1 | { |
2.6. 查看内存信息
1 |
|
2.7. 查看汇编代码和机器码
项目执行过程:
C文件预处理变为i文件
i文件经过编译变为s文件 - 汇编文件
s文件经过汇编变为obj文件 - 目标文件
obj文件经过链接变为exe文件 - 可执行文件
终端输入以下命令可以得到汇编代码
1 | gcc -S main.c |
得到汇编+机器码
1 | gcc -g -o main main.c |
3. 在线语言包
http://www.cplusplus.com/reference/
4. 关键字
C语言中有许多关键字。关键字有特殊的用途,不能用于变量命名
| auto | const | double | float | int | short | struct | unsigned |
|---|---|---|---|---|---|---|---|
| break | continue | else | for | long | signed | switch | void |
| case | default | enum | goto | register | sizeof | typedef | volatile |
| char | do | extern | if | return | static | union | while |
5. 常量
常量是指在程序运行过程中,其值不发生变化的量。常量又可分为整型,实型,字符型和字符串型。
整型常量,实型常量,字符常量是在编译时可以直接编入代码段的常量,字符串型常量是指存放在字符串型常量区中的常量,例如,在字符串“你好”中,双引号中间的汉子就是字符串常量,无论双引号中间的内容是ASCII码字符,还是汉字或其他国家的文字等,都是字符串型常量。
整型 100,125,-100,0
实型 3.14,0.125,-3.789
字符型 ‘a’,’b’,’c’
字符串型 “a”,”abc”
6. 变量
6.1. 含义
变量代表内存中具有特定属性的一个存储单元,它用来存放数据,即变量的值。这些值在程序的执行过程中是可以改变的。
变量名以一个名字代表一个对应的存储单元地址。编译,链接程序时,由编译系统为每个变量名分配对应的内存地址。从变量中取值实际上是通过变量名找到内存中存储单元的地址,并从该存储单元中读取数据。
int a = 3; a就是变量名,s就是变量值,int就是变量存储类型
6.2. 命名规则
C语言规定标识符只能由
字母,数字和下划线三种字符组成,并且第一个字符必须为字母或下划线。3D64就是 错误的C语言区分大小写
C语言要求强制定义。即每个变量必须声明后定义值
变量的命名应该做到
见名知意,即选择具有含义的英文单词作为标识符,且不能与关键字同名
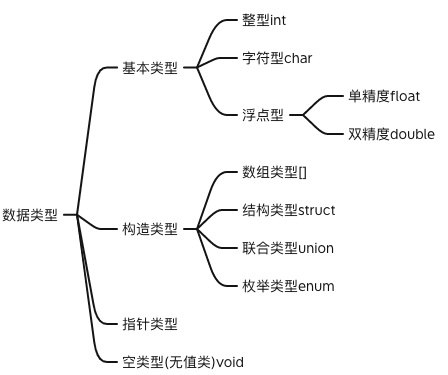
7. 数据类型
裁缝做衣服时需要用到化纤,纯棉,丝绸等不同类型的布料,程序员在编写程序时需要用到各种数据类型,数据类型分为:
7.1. 整型变量
7.1.1. 符号常量 Symbolic Constants
定义一个整型变量时要使用关键字int。
1 |
|
由于整型变量i有自己的内存空间,因此既可以存储整型常量123,又可以存储PI*2,也就是3*2,由define定义的PI为什么是常量呢?
预处理时会清除所有的define,用define将PI定义为3,编译器在预处理后会把代码中出现的所有常量都替换为3,所以PI为常量,不可修改。
7.1.2. 不同进制表示
计算机中只能存储二进制数,即0和1,而在对应的物理硬件上则是高低电平,为了更方便地观察内存中的二进制情况,除正常使用的二进制外,计算机还提供了十六进制和八进制数
- 在计算机中,1字节为8位,1位即二进制的1位,它存储0或1,int型常量的大小为4字节,即32位
设有二进制
0100 1100 0011 0001 0101 0110 1111 1110,其最低位是2的零次方,最高位是2的30次方,最高位为符号位。其对应的八进制数是
011414253376,它以0开头标示,数位的变化范围是0-7,二进制转换为八进制数的方式是,对应的二进制每3位转换为1位八进制数,首先将上面的二进制数按每3 位隔开,得到01 001 100 001 100 010 101 011 011 111 110,然后每3位对应0-7范围内的数进行对应转转,得到八进制数011414253376,由于实际编程时,识别八进制时前面需要加0,所以在前面加了一个0其对应的十进制是
1278301950其对应的十六进制是
0x4c3156FE,它以0x开头标示,数位的变化范围是0-9和A-F,其中A代表10,F代表15,对应的二进制数每4位转换为1位十六进制
7.1.3. 6种整型变量类型
整型变量包括6种类型,其中有符号基本整型与无符号基本整型的最高位所代表的意义不同。
不同整型变量表示的整型数的范围不同,超出范围会发生溢出现象,导致计算出错。
| 类型 | 类型说明符 | 长度 | 整型数的范围 |
|---|---|---|---|
| 有符号基本整型 | (signed) int | 4字节 | -$2^{31}$ ~ $2^{31}$-1 |
| 有符号短整型 | (signed) short (int) | 2字节 | -$2^{15}$ ~ $2^{15}$-1 |
| 有符号基本整型 | (signed) long (int) | 4字节(64位为8字节) | -$2^{31}$ ~ $2^{31}$-1 或 -$2^{63}$ ~ $2^{63}$-1 |
| 无符号基本整型 | unsigned int | 4字节 | 0 ~ $2^{32}$-1 |
| 无符号短整型 | unsigned short (int) | 2字节 | 0 ~ 65535 |
| 无符号长整型 | unsigned long (int) | 4字节(64位为8字节) | 0 ~ $2^{32}$-1 或 0 ~ $2^{64}$-1 |
溢出情况
1 |
|
有符号短整型可以表示的最大值为32767,当对其加1时,b的值等于-32768,为什么会这样?
因为32767对应的十六进制数为0X7fff,加1后变为0x8000,其首位为1,因此变成了一个负数,取这个负数的原码后,就是其本身的值32768,所以0X8000是最小的负数,即-32768,这时就发生了溢出,对32767加1,希望得到的值是32768,但结果却是-32768,因此导致计算结果错误,在使用整型变量时,一定要注意数值的大小,数值不能超过对应整型数的表示范围。
如果在编写的程序汇总数值大于$2^{64}$-1时怎么办?
答案是可以使用数组来存储数值。
7.2. 浮点型数据
7.2.1. 浮点型常量
表示浮点常量的形式有两种
| 小数部分 | 0.123 |
|---|---|
| 指数形式 | 3e-3(3x10${^{-3}}$),即0.003 |
字母e或E代表10的幂次,幂次可正可负。e前面必须有数字,e后面的指数必须为整数
正确示例:1e3,1.8e-3,-123e-6,-.1e-3
错误示例:e3,2.1e3.5,.e3,e
7.2.2. 浮点数精度控制
浮点型变量分为单精度(float)型,双精度(double)型和长双精度(long double)型三类。
| 类型 | 位数 | 数值范围 | 有效数字 |
|---|---|---|---|
| float | 32 | $10^{-37}$~$10^{38}$ | 6~7位 |
| double | 64 | $10^{-307}$~$10^{308}$ | 15~16位 |
| long double | $10^{-4931}$~$10^{4932}$ | 18~19位 |
因为浮点数使用的是指数表示法,所以不用担心数值的范围,也不用去看浮点数的内存。需要注意的是浮点数的精度问题。
1 |
|
赋给a的值为1.23456789e10,加20后,应该得到的值为1.234567892e10,但结果却是1.23456788e+010,变得更小了,这种现象就称为精度丢失,因为float型数据能够表示的有效数字为7位,最多只保证1.23456e10的正确性,要使结果正确,就需要把a和b均改为double型。
7.2.3. 浮点型变量
一般通过float f,double d来定义浮点变量,f占用4个字节空间,d占用8个字节空间。与整型数据的存储方式不同,浮点型数据是按照指数形式存储的,系统把一个浮点型数据分成小数部分(用M表示)和指数部分(用E表示)并分别存放,指数部分采用IEEE754规范化的指数形式,指数也分正负(符号位,用S表示)
| 类型 | 符号位 | 指数部分(阶码) | 小数部分(尾数码) | 总位数 | 偏置值 |
|---|---|---|---|---|---|
| float | 1 | 8 | 23 | 32 | 7FH |
| double | 1 | 11 | 52 | 64 | 3FFH |
IEEE-754浮点型存储标准
以4.5为例,4.5D=100.1B=1.001x$2^2$B
| 格式 | SEEEEEEE | EMMMMMMM | MMMMMMMM | MMMMMMMM |
|---|---|---|---|---|
| 二进制数 | 01000000 | 10010000 | 00000000 | 00000000 |
| 十六进制数 | 40 | 90 | 00 | 00 |
S:S符号位,用来表示正,负,是1时代表负数,是0时代表正数。
E:E代表指数部分,在IEEE-754浮点数标准中的阶码是用移码表示的,移码=真值+偏置值,偏置值=$2^{n-1}$-1,8位的移码的偏置值为$2^{8-1}$-1=127D=0111,1111B,故阶码=0000,0010B+0111,1111B=1000,0001B。所以,还原时指数部分运算前都要减去127,这里的10000001转换为十进制数为129,129-127=2,即实际指数部分为2。
M:M代表小数部分,在IEEE-754标准中的尾数码部分是用原码表示的,且尾数码隐含了最高位1,在计算中需要加上最高位1,即1.M。这里为0010 0000 0000 0000 0000 000。底部左边省略存储了一个1,使用的实际底数表示为1.00100000000000000000000。
反向推导:
计算机并不能计算10的幂次,指数值为2,代表2的2次幂,因此将1.001向左移动2位即可,也就是100.1;然后转换为十进制数,整数部分为4,小数部分为$2^{-1}$,刚好等于0.5,因此十进制为4.5。浮点数的小数部分通过$2^{-1}$+$2^{-2}$+$2^{-3}$+…来近似一个小数的
7.3. 字符型数据
7.3.1. 字符型常量
用单引号括起来的一个字符是字符型常量,且只能包含一个字符,例如,‘a’,‘A’,’1‘是正确的字符型常量,而“abc”,“a”是错误的字符型常量,以\开头的特殊字符称为转义字符,转义字符用来表示回车,退格等功能键。
| 转义字符 | 作用 |
|---|---|
| \n | 换行 |
| \b | 退格 |
| \\ | 反斜杠 |
| \r | 回车 |
| \t | 横向跳格 |
| \0 | 空字母,用于标示字符串的结尾,但它不是空格,无法打印 |
| \ddd | ddd表示1-3位八进制数 |
| \xhh | hh表示1-2位十六进制数 |
例如 abc\rd打印出来的效果是dbc
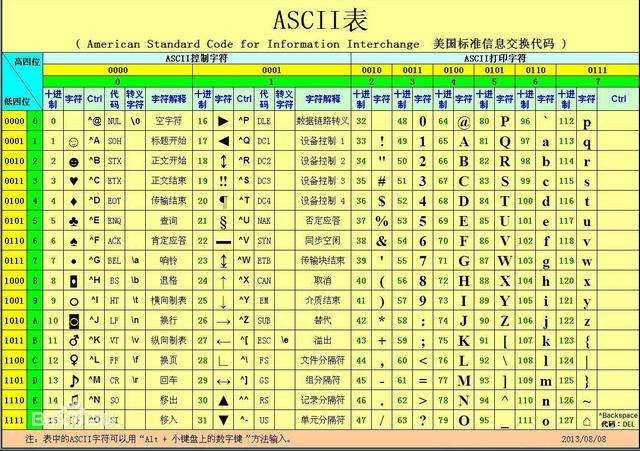
7.3.2. ASCII码表
7.3.3. 字符数据在内存中的存储形式及其使用方法
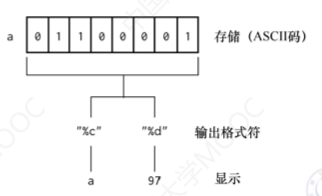
字符型变量使用关键字char进行定义,一个字符型变量占用1字节的空间,一个字符常量存放到一个字符型变量中,实际上并不是把该字符的字型放到内存中,而是把该字符的ASCII码值放到存储单元中。打印字符型变量时,如果以字符形式打印,那么计算机会到ASCII码表中查找字符型变量的ASCII码值,查到对应的字符后会显示对应的字符,这样,字符型数据和整型数据之间就可以通用。字符型数据既可以以字符形式输出,又可以以整数形式输出,还可以通过运算获取想要的各种字符。
1 |
|
对于字符型变量,无论是赋ASCII码值还是赋字符,使用%c打印输出时得到的都是字符,使用%d打印输出时得到的都是ASCII码值,将小写字母转换为大写字母时,小写字母比大写字母数值大32。
7.3.4. 字符串型常量
字符串型常量是由一对双引号括起来的字符序列,例如,”How do you do”,可用语句printf("How do you do")输出一个字符串,但要注意的是,‘a’是字符型常量,而“a”是字符串型常量,二者不同。
C语言规定,在每个字符串常量的结尾加一个字符串结束标志,以便系统据此判断字符串是否结束。C语言规定以字符’\0’作为字符串结束标志。
例如,字符串常量”CHINA”在内存中的存储结果为
| C | H | I | N | A | \0 |
|---|
7.4. 混合运算
字符型(char),整型(int/short/long),浮点型(float/double)数据可以混合运算,运算时,不同类型的数据首先要转换为同一类型,然后进行运算。
不同类型数据的转换级别不同
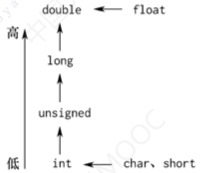
从短字节到长字节的类型转换是由系统自动进行的,编译时不会给出警告;若反向进行,则编译时编译器会给出警告。
7.4.1. 数值按int型运算
C语言中的整型数算术运算总是以默认整型类型的精度进行的,为了获得这个精度,表达式中的字符型和短整型操作数在使用之前会被转换为基本整型(int型)操作数,这种转换被称为整型提升(Integral Promotion)。
1 | char a,b,c; |
其中,b和c的值首先被提升为基本整型数,然后执行加法运算。加法运算的结果将被截短,然后存放到a中,这个例子的结果和使用8位算术运算的结果相同。
但是下列的代码结果默认按照int型运算
1 |
|
为什么采用十六进制打印呢?
这是因为输出时%x是取4字节进行输出的;如果用%d输出,那么可以得到一个负值,用%x输出一个少于4字节的数时,前面补的字节是按照对应数据的最高位来看的,因为字符b的最高位为1,所以其他3字节补的是1,打印出3字节的ff。
为什么把操作分成两步后,b的值就为13?
因为0x93左移移位时,虽然按4字节进行,但是最低一字节的值为0x26。赋值给b后,b内存储的就是0x26,这时再对b进行右移时,单字节拿到寄存器中是按照4字节运算的,但是因为b的最高位为零,因此拿到寄存器中按照4字节运算,前面补的都是零,再右移移位表示除以2,因此得到的值是13。
另外一个场景是两个整型常量做乘法,并赋值给一个长整型变量,对编译器来讲这是按照int型进行的。当两个整型常量值太大时,结果会溢出,无论是在VS中新建Win32控制台应用程序并在32位下执行,还是Linux下将其编译为64位的可执行程序,执行结果均为0
1 |
|
如何解决溢出?
在乘法之前,将整型数强制转换为long型,在32位操作系统下,long long型占8字节而long型占4字节。
1 |
|
在64位程序,Linux操作系统下,转化为long型
1 |
|
7.4.2. 浮点型常量默认按double型运算
浮点型常量默认按8字节运算
1 |
|
第一个打印的值只有7位精度,原因是单精度浮点数f只有4字节的存储空间,能够表示的精度是67位,所以只保证17位是正确的,后面的都是近似值,第二个打印的值是正确的浮点型常量,它是按8字节即double型进行运算的,同时%f会访问寄存器8字节的空间进行浮点运算,因此可以正常输出。
7.5. 类型强制转换场景
整型数进行除法运算时,如果运算结果为小数,那么存储浮点数时一定要进行强制类型转换,否则会出现问题,j的值为2,k的值为2.5
1 |
|
7.6. 数组
数组,构造数据类型,是指一组具有相同数据类型的数据的有序集合
7.6.1. 一维数组格式定义
一维数组定义格式:
1 | //类型说明符 数组名[常量]; |
定义了一个整型数组,数组名为a,它有10个元素
声明数组时要遵循以下规则:
- 数组名的命名规则和变量名的相同,即遵循标识符命名规则;
- 在定义数组时,需要指定数组中元素的个数,方括号中的常量表达式用来表示元素的个数,即数组长度。
- 常量表达式中可以包含常量和符号常量,但不包含变量,也就是说,C语言不允许对数组的大小做动态定义,即数组的大小不依赖于程序运行过程中变量的值。
❌错误的声明
1 | //未定义数组大小 |
7.6.2. 一维数组在内存中的存储
int a[100];
定义的一维数组a在内存中存储在一片连续的区域中,每个元素都是整型元素,占用4字节,数组元素的引用方式为 数组名[下标],即a[i]。
数组元素的下标编号为从0到99,不存在100。
定义数组的一瞬间,数组占据的空间大小就确定下来了
7.6.3. 一维数组的初始化方式
1 | //1. 定义时对数组元素赋初值 |
7.6.4. 字符数组
1 | //定义 |
C语言规定字符串的结束标志为\0,所以字符数组存储的字符串长度必须比字符数组少1字节。
使用scanf函数时,scanf("%s",c); 字符串末尾自动添加\0
7.7. 指针
7.7.1. 定义
内存区域中的每字节都对应一个编号,这个编号就是“地址”。
如果在程序中定义了一个变量,那么在对程序进行编译时,系统就会给这个变量分配内存单元,按变量地址存取变量值的方式称为“直接访问”,如printf(“%d”,i); scanf(“%d”,&i);等;
另一种存取变量值的方式称为“间接访问”,即将变量i的地址存放到另一个变量中,在c语言中,指针变量是一种特殊的变量,它用来存放变量地址。
指针变量定义格式
1 | //基类型 *指针变量名 |
指针与指针变量是两个概念,一个变量的地址称为该变量的“指针”,例如,地址2000是变量i的指针,如果有一个变量专门用来存放另一个变量的地址(即指针),那么称它为“指针变量”,例如,i_pointer就是一个指针变量。
i_pointer 本身占多大的内存空间?
在windows 32位控制台应用程序,寻址范围为32位4字节,即sizeof(i_pointer)=4,如果编写的程序是64位,那么寻址范围就是8字节。
7.7.2. 取地址操作符与取值操作符
取地址操作符为&,也称引用,通过该操作符可以获取一个变量的地址值;
取值操作符为*,也称解引用,通过该操作符可以得到一个地址对应的数据。
1 |
|
通过&i 获取整型变量i的地址值,然后对整型指针变量p进行初始化,p中存储的是整型变量i的地址值,*p获取的是整型变量i的值,p中存储的是一个绝对地址值。
为什么取值时会获取4字节大小的空间呢?
因为p为整型变量指针,每个int型数据占用4字节大小的空间,p在解引用时会访问4字节大小的空间,同时以整型值对内存进行解析。
7.7.3. 注意点
int *i_pointer;指针变量前面的
*表示改变量为指针变量,指针变量为i_pointer,而不是*i_ponter;定义指针变量时必须指定类型。只有整型变量的地址才能放到指向整型变量的指针变量中
i_pointer=&a;执行该语句后,
&*i_pointer的含义是什么?*和&运算符的优先级相同,&*pointer等同于&a,也就是变量a的地址*&a的含义是什么?首先
&a运算得到a的地址,再进行*运算,*&a和*i_pointer的作用一样,都等价于变量a,即*&a等同于a多个指针变量的声明
int *a,*b,*c;而不是
int* a,b,c;
7.7.4. 指针使用场景
7.7.4.1. 指针的传递
通过函数修改变量的值时,形参和变量的地址是不同的。
1 |
|
传入形参a的是值10,而不是i变量的地址值。
栈空间的变化
当main函数开始执行时,系统会为main函数开辟函数栈空间,
当程序走到int i时,main函数的栈空间就会为变量i分配4字节大小的空间。
调用change函数时,系统会为change函数重新分配新的函数栈空间,并为形参变量a分配4字节大小的空间。
在调用change(i)时,实际上是将i的值赋值给a,这种效果称之为值传递。
因此,当change函数的函数栈空间内修改变量a的值后,change函数执行结束,其栈空间就会释放,a不复存在,i的值不会改变。
1 |
|
函数调用仍是值传递,不过此时是将变量i的地址传递给change函数,a是指针变量,内存存储的是变量i的地址,所以通过*a就间接访问到了变量i的值。本身变量a的地址和变量i还是不同的。
7.7.4.2. 指针的偏移
1 |
|
数组名存储着数组的起始地址,其类型为整型指针,赋值给整型变量p。
p+1指向a[1],因为指针变量+1后,偏移的长度是基类型的长度,也就是偏移sizeof(int)。
编译器在编译时,数组取下标的操作正是转换为指针偏移来完成的。
7.7.4.3. 指针与自增,自减运算符
1 |
|
第一个结果为a[0]=2 j=2 *p=7
首先,对于自增运算符一般分为两步,++在后,先进行运算,后进行+1。
此时,j=*p,而p指向数组的第一个元素,所以j=2。
然后是p++,还是*p++?即指针变量操作还是a[0]操作。答案为指针变量操作,p指向了数组的第二个元素。
因为*操作符和++操作符的优先级相同,只有比++优先级高的操作符才会当成一个整体,目前比++操作符高的只有()和[]操作符。
如何让结果为a[0]=3 j=2 *p=3
1 | j=(*p)++; |
第二个结果为a[0]=2 j=7 *p=8
p指向的是元素a[1],j=p[0]++,忽略++操作符,j=a[1]=7,接着对p[0]进行++操作,即对a[1]进行++操作,所以*p=8.
7.7.5. 指针与动态内存申请
C语言的数组长度必须是固定的。因为定义的整型,浮点型,字符型变量都在栈空间中,而栈空间的大小在编译时是确定的。
如果使用的空间大小不确定,那么就使用堆空间。
7.7.5.1. malloc函数
malloc函数用于申请内存
申请空间的单位为字节
其格式为
1 |
|
需要给malloc函数传递的参数是一个整型变量,size_t为基本数据类型;
返回值为void*类型的指针,只能用来存储一个地址而不能进行偏移,因为malloc函数并不知道我们申请的空间用来存放什么类型的数据,所以确定要用来存储什么类型的数据后,都会将void*强制类型转换为对应的类型。
1 |
|
示例中,定义的整型变量i,指针变量p均在main函数的栈空间中,通过malloc函数申请的空间会返回一个堆空间的首地址,把首地址存入变量p。
7.7.5.2. 栈空间,堆空间
栈是计算机系统提供的数据结构,计算机会在底层对栈提供支持,分配专门的寄存器存放栈的地址,压栈操作,出栈操作都有专门的指令执行,从而栈的效率比较高。
堆是C/C++函数库提供的数据结构,它的机制很复杂,例如为了分配一块内存,库函数会按照一定的算法在堆内存中搜索可用的足够大小的空间,如果没有足够大小的空间,那么就有可能调用系统功能增加程序数据段的内存空间,从而分到足够大小的内存,然后返回。显然,堆的效率要比栈低得多。
栈空间由系统自动管理,而堆空间的申请和释放需要自行管理,一般通过free函数释放堆空间。
1 |
|
结果中出现乱码,而且每次执行结果不同
原因为print_stack函数中的字符串存放在栈空间中,函数执行结束后,栈空间会被释放,字符数组c的原有空间已被分配给其他函数使用,因此在调用print_stack函数后,执行puts函数就会出现乱码。而print_malloc函数中字符串存放在堆空间中,堆空间只有在执行free操作后才会释放,否则在进程执行过程中会一直有效。
7.7.5.3. free函数
free函数格式为
1 |
|
其传入的参数为void类型指针,任何指针均可自动转为void*类型指针,把p传递给free函数时,不需要强制类型转换,p的地址值必须是malloc当时返回的地址值,不能进行偏移,也就是malloc和free函数之间不能进行p++等改变p的指向。
原因是申请一段堆内存空间时,内核记录的是起始地址和大小,所以释放时内核用对应的首地址进行匹配,匹配不上时,进程就会崩溃。
1 |
|
程序崩溃

7.7.6. 字符指针与字符数组
1 |
|
编译器在编译时,将字符串型常量存储在数据区中的常量区,这样相同的字符串只会被存储一次,常量区的含义是存储在此区域中的字符串本身不可修改,称之为字符串型常量。
“hello”存储在字符串常量区,占用6字节,首地址赋值给指针变量p。
对于数组变量c,在栈空间有10字节大小的空间,这个初始化将字符串”hello”通过strcpy函数赋值给字符数组c,可以修改c[0]。而p[0]得到的是常量区的空间,不可修改。
p是一个指针变量,它的指向可以修改,重新将”world”字符串的首地址赋值给p,而数组变量c本身存储的是数组首地址,不可修改,c等价于符号常量,c=”world”会造成编译不通。
7.7.7. 二级指针
二级指针也是一种指针,只服务于一级指针的传递与偏移。
整型指针p指向整型变量i,整型指针q指向整型变量j,通过change函数,改变指针变量p的值,指向j。
1 |
|
8. 字符串操作函数
1 |
|
8.1. strlen 统计长度
1 |
|
8.2. strcpy 复制数组
1 |
|
8.3. strcmp 比较大小
大于,则为正值
小于,则为负值
等于,则为零
1 |
|
8.4. strcat 连接
1 |
|
9. 常用的数据输入和输出
C语言通过函数库读取标准输入,然后通过对应函数处理将结果打印到屏幕上。输出函数有printf,putchar,puts,而标准的输入函数有scanf,getchar,gets。
9.1. scanf函数
9.1.1. 介绍
int scanf(const char *format,...);
scanf 函数根据由format指定的格式从stdin读取,并保存数据到其他参数。
scanf函数的返回值是成功赋值的变量数量,发生错误时返回EOF(=-1)。
C语言未提供输入/输出关键字,其输入和输出是通过标准函数库来实现的,C语言通过scanf函数读取键盘输入,键盘输入又被称为标准输入,当scanf函数读取标准输入时,如果还没有输入任何内容,进程会一直处于阻塞状态。
1 |
|
示例代码中,执行输入20,然后回车,显示结果为
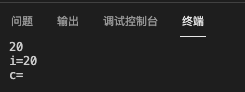
第二个scanf函数读取了缓冲区中的\n,打印其实输出了换行,所以不会阻塞。
9.1.2. 行缓冲
在这种情况下,当在输入和输出中遇到换行符时,将执行真正的I/O操作。这时,输入的字符先存放在缓冲区中,等按下回车键换行时才进行实际的I/O操作。典型代表是标准输入缓冲区(stdin)和标准输出缓冲区(stdout)。
示例代码中,标准输入缓冲区中放入的字符为20\n,输入\n后,scanf函数才开始匹配,scanf函数中的%d匹配整型数20,然后放入变量中,接着进行打印输出,这时\n仍然在标准输入函数(stdin)内。
如果第二个scanf函数为scanf("%d",&i),那么依然会发生阻塞,因为scanf函数在读取整型数,浮点数,字符串时,会忽略回车符,空格符等字符。
忽略是指scanf函数执行时会首先删除这些字符,然后再阻塞。scanf函数匹配一个字符时,会在缓冲区删除对应的字符,因为在执行scanf("%c",&c)语句时,不会忽略任何字符,所以scanf("%c",&c)读取了还在缓冲区中残留的\n。
9.1.3. 具体代码格式
| 代码 | 格式 |
|---|---|
| %c | 字符 char c; scanf(“%c”,&c); |
| %d | 十进制整数 int i; scanf(“%d”,&i); |
| %f,%e,%g | 浮点数 float f; scanf(“%f”,&f); |
| %lf | 双精度浮点数 double d; scanf(“%lf”,&d); |
| %s | 字符串 char str[]; scanf(“%s”,str); |
9.1.4. 循环读取
1 |
|
输入a - 出现循环输出问题?
如果输入的是整数10时,缓冲区中有 10\n,匹配10给变量后,再次输入整数时,缓冲区会删除以前残留的换行符\n。
当输入的不是整数,而是字符时,scanf的返回值是成功赋值的变量数量,即此时为0,而EOF的值是-1,判断 0!=-1,为true,while循环一直匹配,从而出现死循环。
Mac结束循环 control+d
9.2. printf函数
printf函数可以输出各种类型的数据,包括整型,浮点型,字符型,字符串等,实际原理是printf函数将这些类型的数据格式化为字符串后,放入标准输出缓冲区,然后通过\n来刷新标准输出,并将结果显示到屏幕中。
语法格式为
1 |
|
根据format给出的格式打印输出到stdout(标准输出)和其他参数中。
字符串格式(format)由两部分组成:显示到屏幕上的字符和定义printf函数显示的其他参数,指定一个包含文本在内的format字符串,也可以是映射到printf的其他参数“特殊”字符,如下列代码所示:
1 | int age = 18; |
printf函数的具体代码格式:
| 代码 | 格式 |
|---|---|
| %c | 字符 |
| %d | 带符号整数 |
| %f | 浮点数 |
| %s | 字符串 |
| %u | 无符号整数 |
| %x | 无符号十六进制数,用小写字母 |
| %X | 无符号十六进制数,用大写字母 |
| %p | 指针 |
| %% | %符号 |
位于%和格式化命令之间的一个整数被称为最小字段宽度说明符,通常会加上足够多的空格或0使输出足够长,如果填充0,那么就在最小字段宽度说明符前面放置0,另外,也可以使用一个精度修饰符,精度修饰符根据使用的格式代码的不同通常有着不同的含义:
- %f 精度修饰符指定想要的小数位数,例如,%5.2f会至少显示5位数字并带有2位小数的浮点数。
- %s 精度修饰符简单表示一个最大的长度,以补充句点前的最小字段长度。例如,%10s代表字符串共占用10个字符的位置,printf函数默认为右对齐。
- %d 精度修饰符指定输出的整型样式,例如,可以规定整型高位用0填充。
%05d,显示5位数字,不足5位的整型左高位用0填充,超过5位的整型不受影响。 - printf函数的所有输出都是右对齐的,除非在%符号后放置了负号,例如,%-5.2f 会显示5位字符,2位小数位的浮点数并且左对齐。
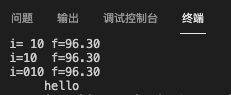
1 |
|
执行结果为整型数载不加符号时靠右对齐,加负号时靠左对齐,整型数加0显示,字符串相对于左边的起始位置右5个空格位置。
9.3. getchar函数
getchar函数可以一次从标准输入读取一个字符,等价于
1 | char c; |
其中getchar函数每次只能读取一个字符,语法格式如下:
1 |
|
示例代码
1 |
|
9.4. putchar函数
putchar函数是向显示设备输出一个字符,语法格式为:
1 |
|
参数ch是要输出的字符,它既可以是字符型变量,整型变量,又可以是常量,输出字符H的代码为putchar('H')。
1 |
|
9.5. gets函数
gets函数类似于scanf函数,用于读取标准输入
1 | char *gets(char *); |
scanf函数在读取字符串时遇到空格就认为读取结束,所以当输入的字符串中存在空格时,可以使用gets函数进行读取。
1 | char c[20]; |
9.6. fgets函数
1 | char *fgets(char * __restrict, int, FILE *); |
OJ不支持gets,因为C11标准去掉了,部分学校机试可以用gets,部分不可以,因此建议使用fgets
1 | char str[10]; |
9.7. puts函数
gets函数的格式为int puts(char *str);
把str字符串写入标准输入,puts执行成功时返回非负值,执行失败时返回EOF。
puts函数会将数组c中存储的字符串打印到屏幕上,同时打印换行,相对于printf函数,puts函数只能用于输出字符串。
1 | char c[20]; |
10. 运算符与表达式
10.1. 运算符分类
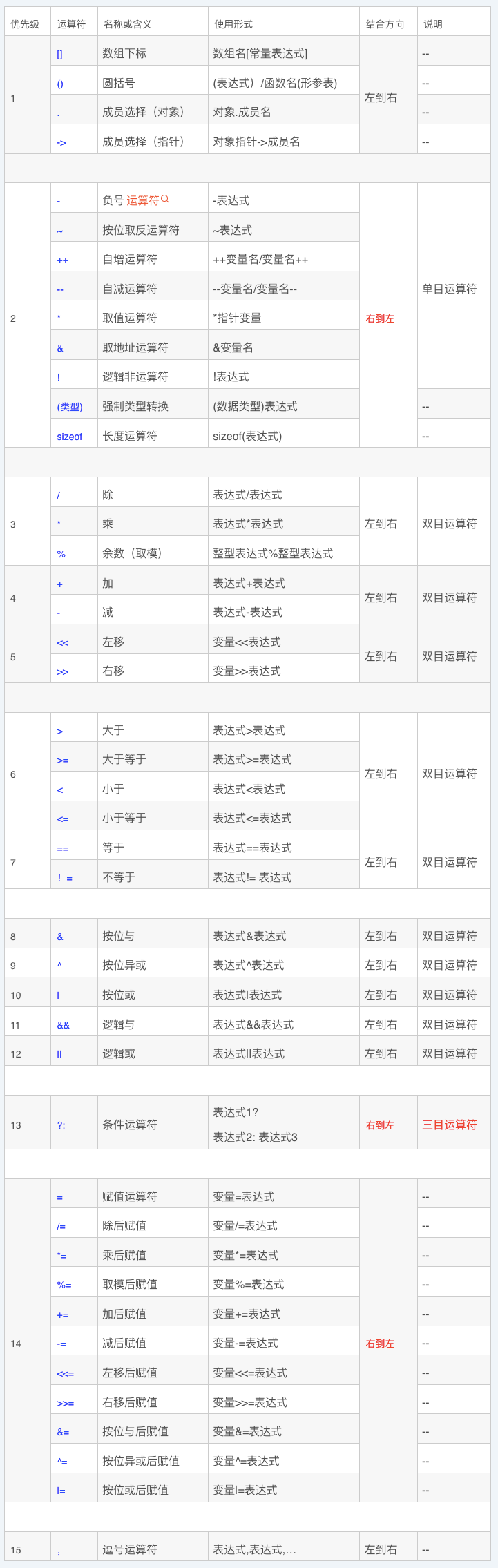
C语言提供了13中类型的运算符:
- 算术运算符(
+ - * / %) - 关系运算符(
> < == >= <= !=) - 逻辑运算符(
! && ||) - 位运算符(
<< >> ~ | ^ &) - 赋值运算符(
=) - 条件运算符(
?:) - 逗号运算符(
,) - 指针运算符(
* &) - 求字节数运算符(
sizeof) - 强制类型转换运算符(
(类型)) - 分量运算符(
. ->) - 下标运算符(
[]) - 其他(
如函数调用运算符())
10.2. C语言符号优先级
同一优先级的运算符,运算次序由结合方向所决定。
简单记就是:! > 算术运算符 > 关系运算符 > && > || > 赋值运算符
此外运算符还有“目”和“结合性”的概念
“目”就是“眼睛”的意思,一个运算符需要几个数就叫“几目”。比如加法运算符+,要使用这个运算符需要两个数,如 3+2。对+而言,3 和 2 就像它的两只眼睛,所以这个运算符是双目的。C语言中大多数的运算符都是双目的,也有单目和三目的。单目运算符比如逻辑非,如!1,它就只有一只眼睛,所以是单目的。整个C语言中只有一个三目运算符,即条件运算符? :。
那么“结合性”是什么呢?上面讲的优先级都是关于优先级不同的运算符参与运算时先计算谁后计算谁。但是如果运算符的优先级相同,那么先计算谁后计算谁呢?这个就是由“结合性”决定的。
比如1+2×3÷4,乘和除的优先级相同,但是计算的时候是从左往右,即先计算乘再计算除,所以乘和除的结合性就是从左往右。
C语言中大多数运算符的结合性都是从左往右,只有三个运算符是从右往左的。一个是单目运算符,另一个是三目运算符,还有一个就是双目运算符中的赋值运算符=。双目运算符中只有赋值运算符的结合性是从右往左的,其他的都是从左往右。
10.3. 算术运算符及算数表达式
算术运算符包含+,-,*,/和%,当一个表达式中同时出现这5种运算符时,先进行乘,除,取余,后进行加,减,也就是乘,除,取余运算符的优先级高于加,减运算符。
除%运算符外,其余几种运算符既适用于浮点数又适用于整型数。
当操作符的两个操作数都是整型数时,它执行整除运算,在其他情况下执行浮点型数除法。
%为取模运算符,它接收两个整型操作数,将左操作数除以右操作数,但它的返回值是余数而不是商。
10.4. 关系运算符及关系表达式
关系运算符>,<,==,>=,<=,!=依次为大于,小于,等于,小于等于,大于等于,是否等于。
由关系运算符组成的表达式称为关系表达式,关系表达式的值只有真或假,对应的值为1或0。
由于C语言中没有布尔类型,所以在C语言中0值代表假,非0值即为真,例如,关系表示式3>4为假,因此整体值为0,而关系表达式5>2为真,因此整体值为1。
关系运算符的优先级低于算术运算符。
判断三个数是否相等时,不可以写为if(5==5==5) ,因为首先5==5得到的结果为1,然后1==5得到的结果为0。判断三个变量a,b,c是否相等,应该写为a==b&&b==c
判断变量是否位于一段值之间时,不能写为3<a<10,无论a是大于3还是小于3,对于3<a这个表达式只有1或0两种结果。由于1和0都是小于10的,所以无论a的值是什么,这个表达式的值始终为真,因此在判断变量a是否大于3且同时小于10时,要写成a>3&&a<10
浮点数是否等于某个值的方法
1 |
|
因为关系元素付的优先级低,所以f-234.56不用加括号,浮点数中存储的是对应数的近似值,只能保证精度为7位。
10.5. 逻辑运算符与逻辑表达式
逻辑运算符!,&&,|| 依次为逻辑非,逻辑与,逻辑或,这和数学上的与,或,非是一致的。
逻辑非的优先级高于算术运算符,逻辑与和逻辑或的优先级低于关系运算符。
逻辑表达式的值只有真或假,对应的值为1或0。
10.6. 位运算符
位运算符 << , >> , ~,|,^,& 依次是左移,右移,按位取反,按位或,按位异或,按位与。
左移<<:高位丢弃,底位补0,相当于乘以2,多用于申请内存时。例如要申请1GB大小的空间,可以使用malloc(1<<30)。
右移>>:底位丢弃,正数的高位补0,无符号数认为是正数,负数的高位补1,相当于除以2,移位比乘法和除法的效率要高,负数右移,对偶数来说是除以2,但对奇数来说是先减1后除以2。例如-8>>1=-4,-7>>1=-4。另外,对于-1来说,无论右移多少位,值永远为-1。
异或^:相同的数进行异或时,结果为0,任何数和0异或的结果是其本身。
按位取反~:数位上的数是1变为0,0变为1。
按位与&和按位或|:用两个数的每一位进行与和或。
10.6.1. 异或-交换变量值
通过异或操作交换两个变量
1 | int a = 5; |
10.6.2. 与-最低位为1的整数
1 | int a = 5; |
10.7. 赋值运算符
左值是那些能够出现在赋值符号左边的东西,右值是那些可以出现在赋值符号右边的东西。
1 | a = b + 25; |
其中,a是一个左值,因为它标识了一个可以存储结果值的地点;b+25是一个右值,因为它指定了一个值。
它们可以互换吗?
因为每个位置都包含一个值,所以原先用作左值的a此时可以作为右值,然而,b+25 不能作为左值,因为它并未标识一个特定的位置,并不对应特定的内存空间,因此,这条赋值语句不能互换。
赋值运算符的优先级是非常低的,仅高于逗号运算符。
10.8. 复合赋值运算符
复合赋值运算符操作是一种缩写形式,使用复合赋值运算符能使对变量的赋值操作变得更加简洁,同时简化了程序,提高了编译效率。
1 | int a = 5; |
10.9. 条件运算符与逗号运算符
条件运算符时C语言中唯一的一种三目运算符,三目运算符代表右三个操作数;双目运算符代表右两个操作数,如逻辑与运算符就是双目运算符;单目运算符代表右一个操作数,如逻辑非运算符就是单目运算符。
1 | int a=5; |
通过三目运算符一定程度上简化了很多if判断代码。
运算符也称为操作符,逗号运算符的优先级最低。
10.10. 自增,自减运算符
自增,自减运算符和其他运算符有很大的区别,因为其他运算符除赋值运算符可以改变变量本身的值外,不会有这种效果,自增,自减就是对变量进行加1,减1操作。
那么有了加法和减法运算符为什么还要发明这种运算符呢?
原因是自增和自减来源于B语言,当时Ken Thompson和Dennis M.Ritchie为了不改变程序员的编写习惯,在C语言中保留了B语言中的自增和自减,因为自增,自减会改变变量的值,所以自增和自减不能用于常量。
1 |
|
输出显示,自增中,++在前进行的是先赋值后+1,++在后进行的是先+1后赋值
11. 选择结构程序设计
11.1. 关系表达式与逻辑表达式
算术运算符(+,-,*,/)的优先级高于关系运算符(<,>,<=,>=,==,!=)
关系运算符优先级高于逻辑与和逻辑或运算符
相同优先级的运算符从左到右进行结合
闰年判断
1 | int year; |
11.2. if语句
if判断为真就执行某些语句,反之不执行这个语句
1 | if(条件){ |
if语句也支持多层嵌套
1 | if(条件){ |
C语言中的else字据从属于最靠近它的不完整的if语句。
11.3. switch语句
判断的一个变量可以等于几个值或几十个值时,使用if和else if语句会导致else if分支非常多,这时可以考虑使用switch语句,语法格式为
1 | switch(表达式){ |
输入一个年份和月份,然后打印对应月份的天数,如输入一个闰年和2月,则输出为29天
1 |
|
switch语句中case后面的常量表达式的值不是按照1到12的顺序排列的,但不影响结果。因为switch语句匹配并不需要常量表达式的值有序排列,输入值等于哪个常量表达式的值,就执行其后的语句,每条语句后需要加上break语句,代表匹配成功一个常量表达式时就不再匹配并跳出switch语句。
改进
1 |
|
如果一个case语句后面没有break语句,那么程序会继续匹配下面的case常量表达式。
原理是只要匹配到1,3,5,7,8,10,12中的任何一个,就不再拿mon与case后的常量表达式的值进行比较,而执行输出语句完毕后执行break语句跳出switch语句。switch与最后加入default的目的是,在所有case后的常量表达式的值都未匹配时,打印输出错误标志或者一些提醒,以便快速掌握代码的执行情况。
12. 循环结构程序设计
12.1. while循环
用来实现“当型”循环结构,形式为while(表达式),当表达式的值非0时,执行while语句中的内嵌语句。其特点是:先判断表达式,后执行语句。当表达式的值非0时,就会执行语句,从而实现语句多次执行的效果。
1 | //计算1到100之间所有整数之和 |
12.2. do/while循环
do/while 语句的特点是:先执行循环体,后判断循环条件是否成立。其一般形式为
1 | do{ |
首先执行一次指定的循环体语句,然后判断表达式,当表达式的值为非零时,返回重新执行循环体语句,如此反复,直到表达式的值等于0为止。
计算1到100之间的所有整数之和。
1 |
|
do/while语句与while语句的差别是,do/while语句第一次执行循环体语句之前不会判断表达式的值,也就是如果i的初值为101,那么依然会进入循环体。
12.3. for循环
C语言中的for循环完全可以代替while循环语句,形式为for(表达式1;表达式2;表达式3)
流程为:
- 计算表达式1
- 判断表达式2。一般表达式2为一个判断句,若其值为0,则退出整个for循环;若其值为1,则执行for语句中的内嵌语句后,执行表达式3
- 转回步骤2继续执行,直到表达式2不满足后,退出for循环。
同样求1到100之间整数之和
1 |
|
12.4. continue
该关键字的作用是跳过循环体中尚未执行的语句。
若计算1到100之间所有奇数之和
1 |
|
12.5. break
break的作用时结束整个循环过程,不再判断执行循环的条件是否成立。
当累加和大于2000时,结束for循环
1 |
|
13. 函数
一个C程序可以由一个主函数和若干个其他函数构成。
函数间的调用关系是,由主函数调用其他函数,其他函数也可以互相调用,同一个函数可以被一个或多个函数调用任意次。
13.1. 示例
func.h,func.c,main.c三个文件放在同一个文件夹下
func.h中存放的是标准头文件的声明和main函数中调用的两个子函数的声明,如果不在头文件中对使用的函数进行声明,那么在编译时会出现警告
1 | //头文件-func.h |
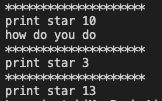
func.c是子函数printstar和print_message的实现,也称为定义
1 |
|
main.c是main函数
1 |
|
终端执行命令
1 | gcc main.c func.c -o main |
输出
13.2. C语言的编译和执行特点
- 一个C程序由一个或多个程序模块组成,每个程序模块作为一个源程序文件。对于较大的程序,通常将程序内容分别放在若干源文件中,再由若干源程序组成一个C程序。这样处理便于编写,分别编译,进而提高调试效率。一个源程序文件可以为多个C程序共用。
- 一个源程序文件由一个或多个函数及其他内容(如命令行,数据定义等)组成。一个源程序文件是一个编译单位,在程序编译时是以源程序文件为单位而不是以函数为单位进行编译的。main.c和func.c分别单独编译,在链接成为可执行文件时,main中调用的函数printstar和print_message才会通过链接去找到函数定义的位置。
- C程序的执行是从main函数开始的,如果在main函数中调用其他函数,那么在调用后会返回main函数中,在main函数中结束整个程序运行。
- 所有函数都是平行的,即在定义函数时是分别进行的,并且是互相独立的。一个函数并不从属于另一个函数,即函数不能嵌套定义。函数间可以互相调用,但不能调用main函数。main函数是由系统调用的,如main函数中调用print_message函数,而print_message函数中又调用printstar函数,这种调用称为嵌套调用。
13.3. 函数的声明与定义的差异
- 函数的定义是指对函数功能的确立,包含指定函数名,函数值类型,形参及其类型,函数体等,它是一个完整的,独立的函数单位。
- 函数的声明的作用是把函数的名字,函数类型及其形参的类型,个数和顺序通知编译系统,以便在调用该函数时编译系统能正确识别函数并检查调用是否合法。
- 隐式声明是指C语言中有几种声明的类型名可以省略。例如,函数如果不显式地声明返回值的类型,那么它默认返回整型;使用旧风格声明函数的形式参数时,如果省略参数的类型,那么编译器默认它们为整型。然而,依赖隐式声明并不是好的习惯,因为隐式声明容易让代码的读者产生疑问;编写者是否有意遗漏了类型名?还是不小心忘记了?显式声明能够清楚滴表达意图。
13.4. 函数的分类与调用
从用户角度来看,函数分为两种:
- 标准函数。即库函数,这是由系统提供的,用户不必自己定义的函数,可以直接使用。如,printf函数,scanf函数。不同的C系统提供的库函数的数量和功能会有一些不同,但许多基本的函数是相同的。
- 用户自己定义的函数,用以解决用户的专门需要。
从函数的形式看,函数分为如下两类:
无参函数。一般用来执行指定的一组操作。在调用无参函数时,主调函数不向被调用函数传递数据。
1
2
3
4类型标识符 函数名(){
声明部分
语句部分
}有参函数。主调函数在调用被调用函数时,通过参数向被调用函数传递数据。
1
2
3
4类型标识符 函数名(形式参数表列){
声明部分
语句部分
}
printstar函数就是有参函数,int i对应的i为形式参数,主调函数和被调用函数之间存在数据传递关系。
在不同的函数之间传递数据时,可以使用的方法如下:
- 参数:通过形式参数和实际参数
- 返回值:用return语句返回计算结果
- 全局变量:外部变量
13.5. 全局变量
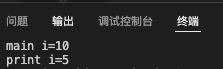
1 |
|
13.5.1. 全局变量存储在哪里
存储在数据段,所以main函数和print函数都是可见的。全局变量不会因为某个函数执行结束而消失,在整个进程的执行过程中始终有效,因此工作中应尽量避免使用全局变量。
局部变量存储在自己的函数对应的栈空间内,函数执行结束后,函数内的局部变量所分配的空间将会得到释放。如果拒不变量与全局变量重名,那么将采取就近原则,即实际获取和修改的值是局部变量的值。
13.5.2. 形参和实参
如果把print(int a)改为print(int i),那么print函数的打印结果会是什么?不变
- 定义函数中指定的形参,如果没有函数调用,那么它们并不占用内存中的存储单元,只有在发生函数调用是,函数print中的形参才被分配内存单元,在调用结束后,形参所站的内存单元也会释放。
- 实参可以是常量,变量或是表达式,但要求它们有确定的值,如,print(i+3)在调用时将实参的值赋给形参。假如print函数有两个形参,如print(int a,int b),那么实际调用print函数时,使用print(i,i++)是不合适的,因为C标准未规定函数调用是从左到右计算还是从右到左计算,因此不同的编译会有不同的标准,造成代码在移植过程中发生非预期错误。
- 在被定义的函数中,必须指定形参的类型,如果实参列表中包含多个实参,那么各参数间用逗号隔开,实参与形参的个数应相等,类型应匹配,且实参与形参应顺序对应,一一传递数据。
- 实参与形参的类型应相同或赋值应兼容。
- 实参向形参的数据传递是单向值传递,只能由实参传给形参,而形参无法传回给实参。在调用函数时,给形参分配存储单元,并将实参对应的值传递给形参,调用结束后,形参单元被释放,实参单元仍保留并维持原值。
13.6. 变量及函数的作用域
13.6.1. 局部变量
在函数内部定义的变量称为内部变量,它只在本函数范围内有效,即只有在本函数内才能使用这些变量,故也称局部变量。
📢注意点:
主函数中定义的变量只在主函数中有效,而不因为在主函数中定义而在整个文件或程序中有效。主函数也不能使用其他函数中定义的变量。
不同函数中可以使用相同名字的变量,它们代表不同的对象,互不干扰。
形式参数也是局部变量。
在一个函数内部,可以在复合语句中定义变量,这些变量只在本复合语句中有效,这种复合语句也称为“分程序’’或”程序块“。即只在离自己最近的花括号内有效,若离开花括号,则在其下面使
用该变量会造成编译不通。
13.6.2. 外部变量
函数之外定义的变量称为外部变量。外部变量可以为本文件中的其他函数共用,它的有效范围是从定义变量的位置开始到本源文件结束,所以也称全程变量。
📢注意点:
- 全局变量在程序的全部执行过程中都占用存储单元,而不是仅在需要时才开辟单元。
- 使用全局变量过多会降低程序的清晰性。在各个函数执行是都可能改变外部变量的值,程序容易出错,因此要有限制地使用全局变量。
- 因为函数在执行时依赖于其所在的外部变量,如果将一个函数移到另一个文件中,那么还要将有关的外部变量及其值一起移过去。然而,如果该外部变量与其他文件的变量同名,那么就会出现问题,即会降低程序的可靠性和通用性。C语言一般要求把程序中的函数做成一个封闭体,除可以通过实参->形参的渠道与外界发生联系外,没有其他渠道。
14. 结构体
C语言提供结构体来管理不同类型的数据组合。
14.1. 结构体的定义
1 | /* |
结构体类型声明要放在main函数之前,这样main函数中才可以使用这个结构体,一般往往把结构体声明放在头文件中。📢注意,结构体类型声明最后一定要加分号,否则会编译不通。
另外,定义结构体变量时,使用struct student来定义,不能只有struct或student,否则也会编译不通,stu是结构体数组变量。
结构体的初始化只能在一开始定义,如果 struct student stu2={1001,"lele",'M',20,98,"Shenzhen"};分为两步: struct student stu2; 和 stu2={1001,"lele",'M',20,98,"Shenzhen"}; 将编译不通。此时只能对它的每个成员单独赋值,如stu.num=1003。
采用”结构体变量名.成员名“的形式来访问结构体成员,例如用stu.num访问学号。在进行打印输出时,必须访问到成员,而且printf的%类型要与各成员匹配。使用scanf读取标准输入时,也必须是各成员取地址,然后进行存储,不可以写成%s,即不可以直接对结构体变量取地址。
整型数据(%d),浮点型数据(%f),字符串性数据(%s)都会忽略空格,但是字符型数据(%c)不会忽略空格,所以如果要读取字符型数据,那么就要在待读取的字符数据与其他数据之间加入空格。
14.2. 结构体对齐
结构体的大小必须是其最大成员的整数倍
1 |
|
14.3. 结构体指针
一个结构体变量的指针就是该变量所占据的内存段的起始地址。
可以设置一个指针变量,用它指向一个结构体变量,此时该指针变量的值是结构体变量的起始地址。
指针变量也可以用来指向结构体数组中的元素。
1 |
|
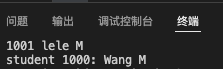
stu就是一个结构体指针,可以对结构student取地址并赋给stu,这样借助成员选择操作符,就可以通过stu访问结构体的每个成员,然后进行打印。
获取成员的方式一种使用(*stu).num ,加括号是因为.的优先级高于*
15. typedef
typedef声明新的类型名来代替已有的类型名
1 |
|
使用stu定义结构体变量和使用struct student定义结构体变量是等价的
使用INTEGER定义变量i和使用int 定义变量i是等价的
pstu等价于struct student *,所以p是结构体指针变量
16. C++的引用
变量
1 | int a; |
指针
1 | int *p=NULL; |
17. const
const int i类型一旦定义,就不能修改,而int类型可以随时修改,因为const int是用来保存一些全局常量的,因此这些常量在编译期间可以修改,但在运行期间不能修改。
听起来这很像宏,其实她确实是用来取代宏的。例如,比较 #define PI 3和 const int Pi=3;如果代码中用到了100次PI(宏),那么代码中就会保存100个常数3。
由于使用常数进行运算的机器代码很多时候要比使用变量时的机器代码长,因此换用100次Pi(const int)后,程序编译后的机器码中就不需要出现100次常量3,而只在需要时引用存储有3的常量。
从汇编的角度看,const定义的常量只给出了对应的内存地址,而不像#define那样给出的是立即数,所以const定义的常量在程序运行过程中只有一份副本,而#define定义的常量在内存中有若干副本,编译器通常不为普通的const常量分配存储空间,而将它们保存在符号表中,这就使得它成为一个编译期间的常量,而没有存储与读内存的操作,因此使得它的效率也很高。
17.1. const char *ptr;
定义一个指向字符常量的指针,其中ptr是一个指向char*类型的常量,不能用ptr来修改所指向的内容,换句话说,*ptr的值为const,不能修改,但是ptr的声明并不意味着它指向的值实际上就是一个常量,而只意味着对ptr而言,这个值是常量。
1 |
|
ptr指向str,而str不是const,可以直接通过str变量来修改str[0]的值,但不能通过ptr指针来修改
char const *ptr 与 const char *ptr等价,通常使用const char *ptr
17.2. char * const ptr;
定义一个指向字符的指针常量,即const指针,不能修改ptr指针,但可以修改该指针指向的内容。
1 |
|
const 直接修饰指针时,指针ptr指向的内容可以修改,但是指针ptr在第一次初始化后,后面不能再对ptr进行赋值,否则会出现编译报错。
18. 文件操作
程序执行时就称为进程,进程运行过程中的数据均在内存中。需要存储运算后的数据时,就需要使用文件。
18.1. C文件概述
文件是指存储在外部介质(如磁盘,磁带)上的数据集合。操作系统(Windows,Linux,Mac等)是以文件为单位对数据进行管理的。
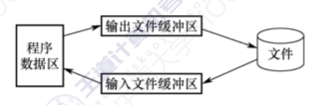
C语言对文件的处理方法如下:
缓冲文件系统:系统自动地在内存区为每个正在使用的文件开辟一个缓冲区,用缓冲文件系统进行的输入/输出称为高级磁盘输入/输出非缓冲文件系统:系统不自动开辟确定大小的缓冲区,而由程序为每个文件设定缓冲区,用非缓冲文件系统进行的输入/输出称为低级输入/输出
缓冲区其实就是一段内存空间,分为读缓冲,写缓冲,C语言缓冲的三种特性如下:
全缓冲:在这种情况下,当填满标准I/O缓存后才进行实际I/O操作。全缓冲的典型代表是对磁盘文件的读写操作行缓冲:在这种情况下,挡在输入和输出中遇到换行符时,将执行真正的I/O操作。这时,输入的字符先存放到缓冲区中,等按下回车键换行时才进行实际的I/O操作。典型代表是标准输入缓冲区(stdin)和标准输出缓冲区(stdout)不带缓冲:不进行行缓冲,标注出错情况(stderr)是典型代表,这使得出错信息可以直接尽快地显示出来
18.2. 文件的打开,读写,关闭
18.2.1. 文件指针介绍
打开一个文件后,得到一个 FILE*类型的文件指针,然后通过该文件指针对文件进行操作,FILE是一个结构体类型
1 | struct _iobuf{ |
fp是一个指向FILE类型结构体的指针变量,可以使fp只想某个文件的结构体变量,从而通过该结构体变量中的文件信息来访问该文件
Windows操作系统下的FILE结构体与Linux操作系统下的FILE结构体中的变量名是不一致的,但是其原理可以互相参考
18.2.2. 文件的打开和关闭
fopen函数用于打开由fname指定的文件,并返回一个关联该文件的流。如果发生错误,那么fopen返回NULL,mode用于决定文件的用途(如输入,输出等),具体形式如下所示:
1 | FILE *fopen(const char *fname,const char *mode); |
常用的mode参数及其各自的意义如下所示
| mode | 意义 |
|---|---|
| r | 打开一个用于读取的文本文件 |
| w | 创建一个用于写入的文本文件 |
| a | 附加到一个文本文件 |
| rb | 打开一个用于读取的二进制文件 |
| wb | 创建一个用于写入的二进制文件 |
| ab | 附加到一个二进制文件 |
| r+ | 打开一个用于读/写的文本文件 |
| w+ | 创建一个用于读/写的文本文件 |
| a+ | 打开一个用于读/写的文本文件 |
| rb+ | 打开一个用于读/写的二进制文件 |
| wb+ | 创建一个用于读/写的二进制文件 |
| ab+ | 打开一个用于读/写的二进制文件 |
fclose函数用于关闭给出的文件流,并释放已关联到流的所有缓冲区。fclose执行成功时返回0,否则返回EOF,具体形式如下:
1 | int fclose(FILE *stream); |
fputc函数用于将字符ch的值输出到fp指向的文件中,如果输出成功,那么返回输出的字符;如果输出失败,那么返回EOF,具体形式如下:
1 | int fputc(int ch, FILE *stream); |
fgetc函数用于从指定的文件中读入一个字符,该文件必须是以读或者读写方式打开的。如果读取一个字符成功,那么赋给ch。如果遇到文件结束符,那么返回文件结束标志EOF,具体形式如下:
1 | int fgetc(FILE *stream); |
具体实现:
输出文本内容
1 |
|
main函数传递参数
假设编译后的可执行文件为test.exe,执行test.exe时,后面跟的参数均是字符串,argv[i]依次指向每个元素,注意参数之间以空格隔开。例如test.exe file1 file2,此时argv[0]是test.exe,argv[1]是file1.txt,argv[2]是file2.txt。
文件名用argv[1]进行传递,打开文件后,得到文件指针fp,如果文件指针fp为NULL,那么表示打开失败,这时可用perror函数得到打开失败的原因,如果未新建一个文件,即文件不存在,那么会出现失败提示。
perror(fopen)出现的错误为 fopen: No such file or directory
冒号之前的内容是写入在perror函数的字符串,冒号之后的内容是perror提示的函数失败原因。
fgetc文件打开成功后,使用fgetc函数可以读取文件的每个字符。然后循环打印整个文件,读到文件结尾时返回EOF,所以通过判断返回值是否等于EOF就可以确定是否读到问价结尾。
写入到文本
1 |
|
18.2.3. fread,fwrite函数
fread函数
1 | int fread(void *buffer, size_t size,size_t num,FILE *stream); |
fwrite函数
1 | int fwrite(const void *buffer,size_t size, size_t count,FILE *stream); |
buffer是一个指针,对fread来说它是读入数据的存放地址,对fwrite来说它是输出谁的地址(均指起始地址);
size是要读写的字节数;
num/count是要进行读写多少size字节的数据项;
fread函数的返回值是读取的内容数量;fwrite写成功后的返回值是已写对象的数量
具体实现fread+fwrite
1 |
|
18.2.4. fseek函数
改变文件的位置指针,其具体调用形式:
1 | int fseek(FILE *stream,long offset,int origin); |
其中 fseek的说明
1 | fseek(文件类型指针,位移量,起始点); |
起始点
文件开头 SEEK_SET 0
当前位置 SEEK_CUR 1
文件末尾 SEEK_END 2
位移量是指以起始点为基点,向前移动的字节数,一般要求为long型,fseek函数调用成功返回零,调用失败时返回非零
存储问题
1 |
|
文件内容为:
文件中存储的是ASCII表中十进制9的对应转义字符 \t(横向制表符)
用【hex Editor插件】打开文件内容为09 00 00 00
fread 和 fwrite函数既可以以文本方式对文件进行读写,又可以以二进制方式对文件进行读写,以“r+”即文本方式打开文件进行读写时,向文件内写入9,写入完毕后会将文件位置指针指向4字节的位置,如果要从文件头读取,那么就必须通过fseek函数偏移到文件头。
18.2.5. fgets,fpus函数
fgets函数从给出的文件流中读取[num-1]个字符,并且把它们转储到str(字符串)中,fgets在到达行末时停止,fgets成功时返回str(字符串),失败时返回NULL,读到文件结尾时返回NULL,其具体形式:
1 | char *fgets(char *str, int num, FILE *stream); |
使用fgets函数可以一次读取文件的一行,这样就可以轻松地统计文件的行数,同时,读取一行字符串后,可以按照自己的方式进行单词分割当操作,注意,在做一些在线评测题目时,用于fgets函数的str不能过小,否则可能无法读取”\n“,导致行数统计出错。
fpus函数把str(字符串)指向的字符写到给出的输出流,成功时返回非负值,失败时返回EOF,其具体形式:
1 | int fputs(const *str, FILE *stream); |
fputs函数向文件中写入一个字符串,不会额外写入一个”\n“。
具体实现
1 |
|
18.2.6. ftell函数
ftell函数返回stream当前的文件位置,发生错误时返回-1,想知道位置指针距离文件开头的位置时,就需要用到ftell函数,其具体形式:
1 | long ftell(FILE *stream); |
ftell与fseek使用
1 |
|
向文件中写入”hello\nworld“,因为是文本方式,所以总计11字节,通过fseek函数向前偏移5字节后,用ftell函数得到的位置指针距离文件开头即为7,这时再用fread函数读取文件内容,得到的是”world“。
19. 网络编程
19.1. 网络协议
网络协议为计算机网络中进行数据交换而建立的规则,标准或约定的集合
有了规则,任何两台计算机就可以在遵循TCP/IP协议的前提下顺畅的进行通信
TCP/IP协议总计分为4层,应用层,传输层,网络层,网络接口层